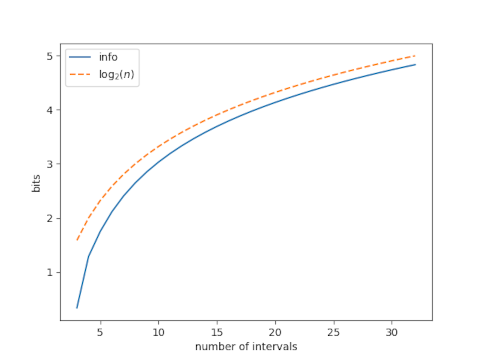
I got an evaluation copy of The Best Writing on Mathematics 2021 yesterday. One article jumped out as I was skimming the table of contents: A Zeroth Power Is Often a Logarithm Yearning to Be Free by Sanjoy Mahajan. Great title.
There are quite a few theorems involving powers that have an exceptional case that involves a logarithm. The author opens with the example of finding the antiderivative of xn. When n ≠ −1 the antiderivative is another power function, but when n = −1 it’s a logarithm.
Another example that the author mentions is that the limit of power means as the power goes to 0 is the geometric mean. i.e. the exponential of the mean of the logarithms of the arguments.
I tried to think of other examples where this pattern pops up, and I thought of a couple related to entropy.
q-logarithm entropy
The definition of q-logarithm entropy takes Mahajan’s idea and runs it backward, turning a logarithm into a power. As I wrote about here,
The natural logarithm is given by
and we can generalize this to the q-logarithm by defining
And so ln1 = ln.
Then q-logarithm entropy is just Shannon entropy with natural logarithm replaced by q-logarithm.
Rényi entropy
Quoting from this post,
If a discrete random variable X has n possible values, where the ith outcome has probability pi, then the Rényi entropy of order α is defined to be
for 0 ≤ α ≤ ∞. In the case α = 1 or ∞ this expression means the limit as α approaches 1 or ∞ respectively.
…
When α = 1 we get the more familiar Shannon entropy:


In this case there’s already a logarithm in the definition, but it moves inside the parentheses in the limit.
And if you rewrite
pα
as
p pα−1
then as the exponent in pα−1 goes to zero, we have a logarithm yearning to be free.