Hadley Wickham posted a photo on Twitter back in September illustrating R list indices with pepper:
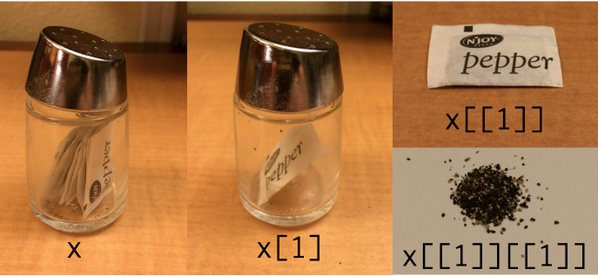
Then a few days ago, Jenny Bryan posted on Twitter her follow up, an analogous photo for XML:

More R posts
Around 2000, some people believed that nearly all programming would be a matter of transporting and transforming XML. XML would be the universal data format, and all software would be a matter of transforming XML. If that were the case, then it would be very handy to use a language designed especially for transforming XML. That language was XSLT.
I’m sure some programmers write XSLT on a daily basis, and there’s probably a large amount of machine-generated XSLT out there. But it’s safe to say XSLT never became extremely popular. Maybe because the syntax is awkward. Not many developers like to write lots of angle brackets. Or maybe the declarative/functional style of the language isn’t as comfortable as a more imperative style of programming for most developers. I don’t really know. I thought XSLT sounded like a good idea, but I never learned it. My experience with XSLT consists of a few dozen lines I wrote six or seven years ago.
I migrated the HTML pages on my website to XHTML this weekend. I’ve been hesitant to do this after hearing a couple horror stories of how a slight error could have big consequences (for example, see how extra slashes caused Google to stop indexing CodeProject [link died]) but I took the plunge. Mostly this was a matter of changing <br> to <br /> etc. But I did discover a few errors such as missing </p> tags. I was surprised to find such things because I had previously validated the site as HTML 4.01 strict.
I thought that HTML entities such as β for the Greek letter β were illegal in XHTML. Apparently not. Three validators (Microsoft Expression Web 2, W3C, and WDG) all seem to think they’re OK. Apparently they’re defined in XHTML though not in XML in general. I looked at the official W3C docs and didn’t see anything ruling these out.
Also, I’ve read that <i> and <b> are not allowed in strict XHTML. That’s what Elliotte Rusty Harold says in Refactoring HTML, and he certainly knows more about (X)HTML that I do. But the three validators I mentioned before all approved of these tags on pages marked as XHTML strict. I changed the <i> and <b> tags to <em> and <strong> respectively just to be safe, but I didn’t see anything in the W3C docs suggesting that the <i> and <b> tags were illegal or even deprecated. (I understand that italic and bold refer to presentation rather than content, but it seems pedantic to me to suggest that <em> and <strong> are any different than their frowned-upon counterparts.)
Suppose you have an XML sitemap and you want to extract a flat list of URLs. This PowerShell code will do the trick.
([ xml ] (gc sitemap.xml)).urlset.url | % {$_.loc}
This code calls Get-Content, using the shortcut gc, to read the file sitemap.xml and casts the file to an XML document object. It then makes an array of all blocks of XML inside a <url> tag. It then pipes the array to the foreach command, using the shortcut %, and selects the content of the <loc> tag which is the actual URL.
Now if you want to filter the list further, say to pull out all the PDF files, you can pipe the previous output to a Where-Object filter.
([ xml ] (gc sitemap.xml)).urlset.url | % {$_.loc} |
? {$_ -like *.pdf}
This code uses the ? shortcut for the Where-Object command. The -like filter uses command line style matching. You could use -match to filter on a regular expression.
Related resources: PowerShell script to make an XML sitemap, Regular expressions in PowerShell
It’s not hard to use Greek letters and math symbols in (X)HTML, but apparently it’s not common knowledge either. Many pages insert little image files every time they need a special character. Such web pages look a little like ransom notes with letters cut from multiple sources. Sometimes this is necessary but often it can be avoided.
I’ve posted a couple pages on using Greek letters and math symbols in HTML, XML, XHTML, TeX, and Unicode. I included TeX because it’s the lingua franca for math typography, and I included Unicode because the X(HT)ML representation of symbols is closely related to Unicode.
The notes give charts for encoding Greek letters and some of the most common math symbols. They explain how HTML and XHTML differ in this context and also discuss browser compatibility issues.
XHTML is essentially a stricter form of HTML, but not quite. For the most part, you can satisfy the requirements of both standards at the same time. However, when it comes to closing tags, the two standards are incompatible. For example, the line break tag in HTML is <br> but in XHTML is <br/>. Most browsers will tolerate the unnecessary backslash before the closing tag in HTML, especially if you put a space before it. But it’s not strictly correct.
So is this just a pedantic point of markup language grammar? Chris Maunder says an error with closing tags caused Google to stop indexing his website. He had XHTML-style end tags but had set his DOCTYPE to HTML.
I’ve also heard of browsers refusing to render a page at all because it had DOCTYPE set to XHTML but contained an HTML entity not supported in XHTML. I believe the person reporting this said that he had run the XHTML page through a validator that failed to find the error. Unfortunately I’ve forgotten where I saw this. Does anyone know about this?
Here’s an interesting graph from Marko Pinteric comparing Microsoft Word and Donald Knuth’s LaTeX.

According to the graph, LaTeX becomes easier to use relative to Microsoft Word as the task becomes more complex. That matches my experience, though I’d add a few footnotes.
See Charles Petzold’s notes about the lengths he went to in order to produce is upcoming book in Word. I imagine someone of less talent and persistence than Petzold could not have pulled it off using Word, though they would have stood a better chance using LaTeX.
Before the 2007 version, Word documents were stored in an opaque binary format. This made it harder to compare two documents. A version control system, for example, could not diff two Word documents the same way it could diff two text files. It also made Word documents difficult to troubleshoot since you had no way to look beneath the WYSIWYG surface.
However, a Word 2007 document is a zip file containing a directory of XML files and embedded resources. You can change the extension of any Office 2007 file to .zip and unzip it, inspect and possibly change the contents, the re-zip it. This opens up many new possibilities.
I’ve written some notes that may be useful for people wanting to try out LaTeX on Windows.
Here’s some Python code to create a sitemap in the format specified by sitemaps.org and read by search engines. Download the file sitemapmaker.txt and change the extension from .txt to .py.
Change the url variable in the script before running it or else you’ll point search engines to my website rather than yours. Also, edit the file extensions_to_keep variable if you want to index any file types besides HTML and PDF.
Copy the file sitemapmaker.py to the directory on your computer where you have your files. Run the script and direct its output to a file, sitemapmaker.py > sitemap.xml. See sitemaps.org for instructions on how to let search engines know about your sitemap.
This code assumes all the files to index in your sitemap are in one directory, the directory you run the script from. It also assumes the timestamps on your computer match those on your web server. Optional fields are left out of the sitemap.