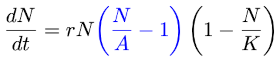This post will discuss two scripting languages, but that’s not what the post is really about. It’s really about expressiveness and (or versus) productivity.
***
I was excited to discover the awk programming language sometime in college because I had not used a scripting language before. Compared to C, awk was high-level luxury.
Then a few weeks later someone said “Have you seen Perl? It can do everything awk can do and a lot more.” So I learned Perl. Was that or a good idea or a bad idea? I’ve been wondering about that for years.
Awk versus Perl is a metaphor for a lot of other decisions.
***
Awk is a very small language, best suited for working with tabular data files. Awk implicitly loops over a file, repeating some code on every line of a file. This makes it possible to write very short programs, programs so short that they can be typed at the command line, for doing common tasks. I am continually impressed by bits of awk code I see here and there, where someone has found a short, elegant solution to a problem.
Because awk is small and specialized, it is also efficient at solving the problems it is designed to solve. The previous post gives an example.
The flip side of awk being small and specialized is that it can be awkward to use for problems that deviate from its sweet spot.
***
Perl is a very expressive programming language and is suitable for a larger class of problems than awk is. Awk was one of the influences in the design of Perl, and you can program in an awk-like subset of Perl. So why not give yourself more options and write Perl instead?
Expressiveness is mostly good. Nobody is forcing you to use any features you don’t want to use and it’s nice to have options. But expressiveness isn’t a free option. I’ll mention three costs.
- You might accidentally use a feature that you don’t intend to use, and rather than getting an error message you get unexpected behavior. This is not a hypothetical risk but a common experience.
- If you have more options, so does everyone writing code that you might need to debug or maintain. “Expressiveness for me but not for thee.”
- More options means more time spent debating options. Having too many options dissipates your energy.
***
You can mitigate #1 by turning on warnings available in later versions of Perl. And you can mitigate #2 and #3 by deciding which language features you (or your team) will use and which features you will avoid.
But if you use a less expressive language, these decisions have been made for you. No need to decide on and enforce rules on features to shun. Avoiding decision fatigue is great, if you can live with the decisions that have been made for you.
The Python community has flourished in part because the people who don’t like the language’s design choices would rather live with those choices than leave these issues permanently unsettled.
***
Bruce Lee famously said “I fear not the man who has practiced 10,000 kicks once, but I fear the man who has practiced one kick 10,000 times.” You could apply that aphorism by choosing to master a small language like awk, learning not just its syntax but its idioms, and learning it so well that you never need to consult documentation.
Some people have done this, mastering awk and a few other utilities. They write brief scripts that do tasks that seem like they would require far more code. I look at these scripts expecting to see utilities or features that I didn’t know about, but usually these people have combined familiar pieces in a clever way.
***
Some people like to write haiku and some free verse. Hedgehogs and foxes. Scheme and Common Lisp. Birds and Frogs. Awk and Perl. So the optimal size of your toolbox is to some extent a matter of personality. But it’s also a matter of tasks and circumstances. There are no solutions, only trade-offs.