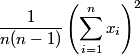On Tuesday I posted a note about computing sample variance or sample standard deviation. I was recommending a method first proposed by B. P. Welford in 1962 and described by Donald Knuth in his magnum opus.
A comment on that post suggested that computing the variance directly from the definition

might be just as accurate, though it requires two passes through the data. My initial reaction was that this would not be as accurate, but when I thought about it more I wasn’t so sure. So I did an experiment.
I compared three methods of computing sample variance: Welford’s method, the method I blogged about; what I’ll call the sum of squares method, using the formula below

and what I’ll call the direct method, the method that first computes the sample mean then sums the squares of the samples minus the mean.
I generated 106 (1,000,000) samples from a uniform(0, 1) distribution and added 109 (1,000,000,000) to each sample. I did this so the variance in the samples would be small relative to the mean. This is the case that causes accuracy problems. Welford’s method and the direct method were correct to 8 significant figures: 0.083226511. The sum of squares method gave the impossible result −37154.734.
Next I repeated the experiment shifting the samples by 1012 instead of 109. This time Welford’s method gave 0.08326, correct to three significant figures. The direct method gave 0.3286, no correct figures. The sum of squares method gave 14233226812595.9.
Based on the above data, it looks like Welford’s method and the direct method are both very good, though Welford’s method does better in extreme circumstances. But the sum of squares method is terrible.
Next I looked at an easier case, shifting the uniform samples by 106. This time Welford’s method was correct to 9 figures and the direct method correct to 13 figures. The sum of squares method was only correct to 2 figures.
I repeated the three cases above with normal(0, 1) samples and got similar results.
In summary, the sum of squares method is bad but the other two methods are quite good. The comment that prompted this post was correct.
The advantage of Welford’s method is that it requires only one pass. In my experiments, I generated each sample, updated Welford’s variables, and threw the sample away. But to use the direct method, I had to store the 1,000,000 random samples before computing the variance.
Update: See this followup post for a theoretical explanation for why the sum of squares method is so bad while the other methods are good. Also, the difficulties in computing sample variance show up in computing regression coefficients and in computing Pearson’s correlation coefficient.