Today I needed to compute an integral similar to this:
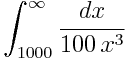
I used the following SciPy code to compute the integral:
from scipy.integrate import quad
def f(x):
return 0.01*x**-3
integral, error = quad(f, 1000, sp.inf, epsrel = 1e-6)
print integral, error
My intention was to compute the integral to 6 significant figures. (epsrel is a shortened form of epsilon relative, i.e. relative error.) To my surprise, the estimated error was larger than the value of the integral. Specifically, the integral was computed as 5.15 × 10-9 and the error estimate was 9.07 × 10-9.
What went wrong? The integration routine quad lets you specify either a desired bound on your absolute error (epsabs) or a desired bound on your relative error (epsrel). I assumed that since I specified the relative error, the integration would stop when the relative error requirement was met. But that’s not how it works.
The quad function has default values for both epsabs and epsrel.
def quad(... epsabs=1.49e-8, epsrel=1.49e-8, ...):
I thought that since I did not specify an absolute error bound, the bound was not effective, or equivalently, that the absolute error target was 0. But no! It was as if I’d set the absolute error bound to 1.49 × 10-8. Because my integral is small (the exact value is 5 × 10-9) the absolute error requirement is satisfied before the relative error requirement and so the integration stops too soon.
The solution is to specify an absolute error target of zero. This condition cannot be satisfied, and so the relative error target will determine when the integration stops.
integral, error = quad(f, 1000, sp.inf, epsrel = 1e-6, epsabs = 0)
This correctly computes the integral as 5 × 10-9 and estimates the integration error as 4 ×10-18.
It makes some sense for quad to specify non-zero default values for both absolute and relative error, though I imagine most users expect small relative error rather than small absolute error, so perhaps the latter could be set to 0 by default.
