Suppose you want to create a background image that tiles well. You’d like it to be periodic horizontally and vertically so that there are no obvious jumps when the image repeats.
Functions like sine and cosine are period along the real line. But if you want to make a two-dimensional image by extending the sine function to the complex plane, the result is not periodic along the imaginary axis but exponential.
There are functions that are periodic horizontally and vertically. If you restrict your attention to functions that are analytic except at poles, these doubly-periodic functions are elliptic functions, a class of functions with remarkable properties. See this post if you’re interested in the details. Here we’re just after pretty wallpaper. I’ll give Python code for creating the wallpaper.
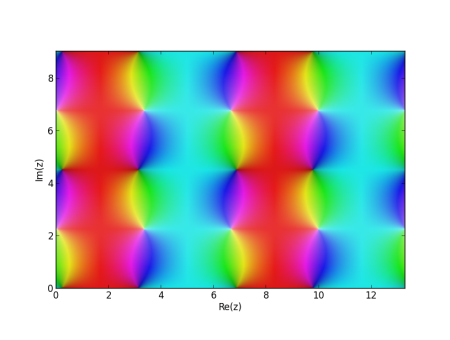
Here I’ll take a particular elliptic function sn(x). This is one of the Jacobi elliptic functions, somewhat analogous to the sine function, and use its phase portrait. Phase portraits use hue to encode the phase of a complex number, the θ value when a complex number is written in polar coordinates. The brightness of the color indicates the magnitude, the r value in polar coordinates.
Here’s the plot of sn(z, 0.2). (The sn function takes a parameter m that I arbitrarily chose as 0.2.) The plot shows two periods, horizontally and vertically. I included two periods so you could more easily see how it repeats. If you wanted to use this image as wallpaper, you could use 1/4 of the image, one period in each direction, to get by with a smaller image.
Here’s the Python code that was used to create the image.
from mpmath import cplot, ellipfun, ellipk
sn = ellipfun('sn')
m = 0.2
x = 4*ellipk(m) # horizontal period
y = 2*ellipk(1-m) # vertical period
cplot(lambda z: sn(z, m) - 0.2, [0, 2*x], [0, 2*y], points = 100000)
I subtracted 0.2 from sn just to shift the color a little. Adding a positive number shifts the color toward red. Subtracting a positive number shifts the color toward blue. You could also multiply by some constant to increase or decrease the brightness.
You could also play around with other elliptic functions, described in the mpmath documentation here. And you can find more on cplot here. For example, you could supply your own function for how phase is mapped to color. The saturated colors used by default are good for mathematical visualization, but more subtle colors could be better for aesthetics.
If you make some interesting images, leave a comment with a link to your image and a description of how you made it.
Read more: Applied complex analysis