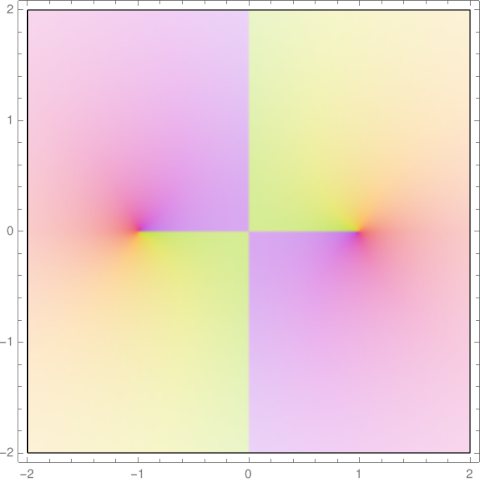
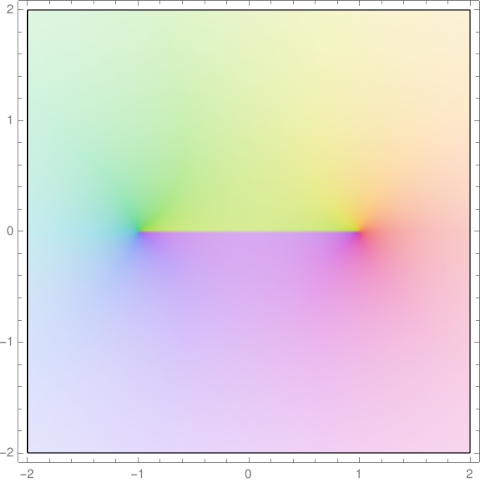
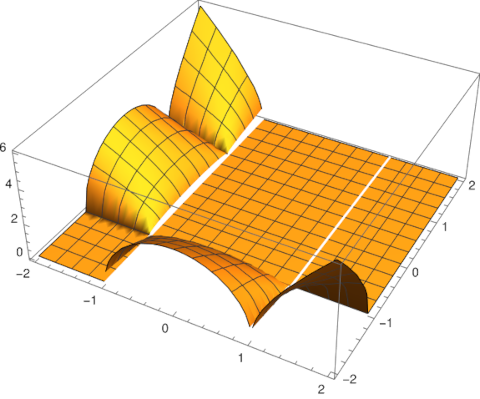
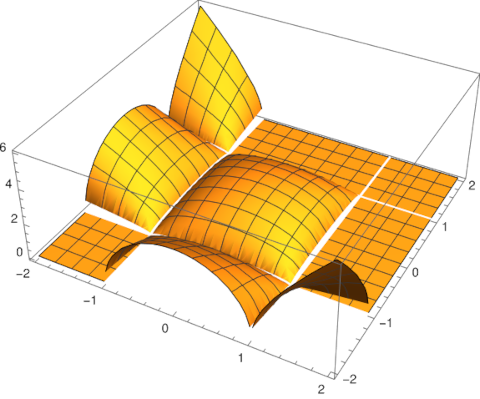
I was thinking more about the cosine approximation to the Gaussian
exp(−z²) ≈ (1 + cos(sin(z) + z))/2
that I wrote about last week. The two expressions above are close along the real axis but not along the imaginary axis.
If z = iy, the right side grows much faster than the left, behaving like exp(exp(y)).
This led to me looking up the power series for the double exponential function exp(exp(y)). This is an interesting series because the coefficient of xn is
e Bn / n!
where Bn is the nth Bell number, which equals the number of ways to partition a set of n labeled items [1]. And of course n! is the number of ways to permute a set of n labeled items. So the nth coefficient in the power series for exp(exp(y)) is the ratio of the number of partitions to permutations for a set of n labeled things, multiplied by e.
The number of ways to partition a set of n things grows quickly as n increases, almost as quickly as the number of permutations, and so the series for the double exponential function converges very slowly.
Computing
SymPy has a function bell for computing Bell numbers, so you could compute the ratio of partitions to permutations as follows.
from sympy import bell, factorial f = lambda n: bell(n)/factorial(n)
This returns a number of type sympy.core.numbers.Rational and so the result is exact. You can cast it to float for convenience.
Asymptotics
If we look at only the terms in the asymptotic series for log Bn and log n! that grow with n we have
log Bn ~ n log n − n log log n
log n! ~ n log n − ½ log n
and so
log( Bn / n! ) ~ ½ log n − n log log n
There’s also an asymptotic series for log( Bn / n! ) involving the Lambert W function:
log( Bn / n! ) ~ n/r − 1 − n log r
where r = W(n).
Related posts
[1] It’s important that the items are labeled. Partition numbers are the number of partitions of an unlabeled set. Partition numbers are much smaller than Bell numbers.