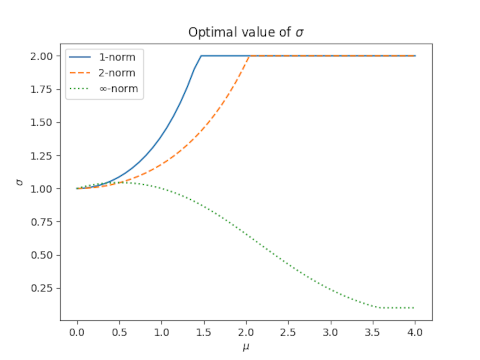
Differential privacy protects user privacy by adding randomness as necessary to the results of queries to a database containing private data. Local differential privacy protects user privacy by adding randomness before the data is inserted to the database.
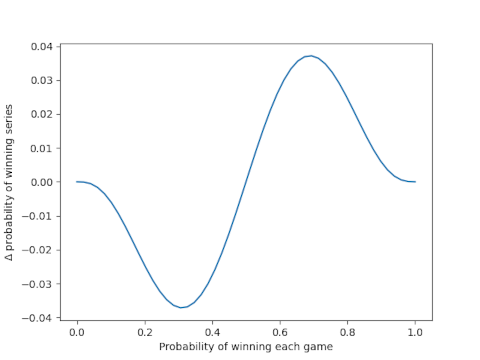
Using the visualization from this post, differential privacy takes the left and bottom (blue) path through the diagram below, whereas local differential privacy takes the top and right (green) path.
The diagram does not commute. Results are more accurate along the blue path. But this requires a trusted party to hold the identifiable data. Local differential privacy does not require trusting the recipient of the data to keep the data private and so the data must be deidentified before being uploaded. If you have enough data, e.g. telemetry data on millions of customers, then you can statistically afford to randomize your data before storing it.
I gave a simple description of randomized response here years ago. Randomized response gives users plausible deniability because their communicated responses are not deterministically related to their actual responses. That post looked at a randomized response to a simple yes/no question. More generally, you could have a a question with k possible answers and randomize each answer to one of ℓ different possibilities. It is not necessary that k = ℓ.
A probability distribution is said to be ε-locally differentially private if for all possible pairs of inputs x and x′ and any output y, the ratio of the conditional probabilities of y given x and y given x′ is bounded by exp(ε). So when ε is small, the probability of any given output conditional on each possible input is roughly the same. Importantly, the conditional probabilities are not exactly the same, and so one can recover some information about the unrandomized response in aggregate via statistical means. However, it is not possible to infer any individual’s unrandomized response, assuming ε is small.
In the earlier post on randomized response, the randomization mechanism and the inference from the randomized responses were simple. With multiple possible responses, things are more complicated. You could choose different randomization mechanisms and different inference approaches for different contexts and priorities.
With local differential privacy, users can share their data without trusting the data recipient to keep the data private; in a real sense the recipient isn’t receiving personal data at all. The recipient is receiving the output of a stochastic process which is weakly correlated with individual data, but isn’t receiving individual data per se.
Local differential privacy scales up well, but it doesn’t scale down well. When ε is small, each data contributor has strong privacy protection, but the aggregate data isn’t very useful unless so many individuals are represented in the data that the randomness added to the responses can largely be statistically removed.