A century ago the German army used a field cipher that transmitted messages using only six letters: A, D, F, G, V, and X. These letters were chosen because their Morse code representations were distinct, thus reducing transmission error.
The ADFGVX cipher was an extension of an earlier ADFGV cipher. The ADFGV cipher was based on a 5 by 5 grid of letters. The ADFGVX extended the method to a 6 by 6 grid of letters and digits. A message was first encoded using the grid coordinates of the letters, then a transposition cipher was applied to the sequence of coordinates.
This post revisits the design of the ADFGVX cipher. Not the encryption method itself, but the choice of letters used for transmission. How would you quantify the difference between two Morse code characters? Given that method of quantification, how good was the choice of ADFGV or its extension ADFGVX? Could the Germans have done better?
Quantifying separation
There are several possible ways to quantify how distinct two Morse code signals are.
Time signal difference
My first thought was to compare the signals as a function of time.
There are differing conventions for how long a dot or dash should be, and how long the space between dots and dashes should be. For this post, I will assume a dot is one unit of time, a dash is three units of time, and the space between dots or dashes is one unit of time.
The letter A is represented by a dot followed by a dash. I’ll represent this as 10111: on for one unit of time for the dot, off for one unit of time for the space between the dot and the dash, and on for three units of time for the dash. D is dash dot dot, so that would be 1110101.
We could quantify the difference between two letters in Morse code as the Hamming distance between their representations as 0s and 1s, i.e. the number of positions in which the two letters differ. To compare A and D, for example, I’ll pad the A with a couple zeros on the end to make it the same length as D.
A: 1011100
D: 1110101
x x x
The distance is 3 because the two sequences differ in three positions. (Looking back at the previous post on popcount, you could compute the distance as the popcount of the XOR of the two bit patterns.)
A problem with this approach is that it seems to underestimate the perceived difference between F and G.
F: ..-. 1010111010
G: --. 1110111010
x
These only differ in the second bit, but they sound fairly different.
Symbolic difference
The example above suggests maybe we should compare the sequence of dots and dashes themselves rather than compare their corresponding time signals. By this measure F and G are distance 4 apart since they differ in every position.
Other possibilities
Comparing the symbol difference may over-estimate the difference between U (..-) and V (...-). We should look at some combination of time signal difference and symbolic difference.
Or maybe the thing to do would be to look at something like the edit distance between letters. We could say that U and V are close because it only takes inserting a dot to turn a U into a V.
Was ADFGV optimal?
There are several choices of letters that would have been better than ADFGV by either way of measuring distance. For example, CELNU has better separation and takes about 14% less time to transmit than ADFGV.
Here are a couple tables that give the time distance (dT) and the symbol distance (dS) for ADFGV and for CELNU.
|------+----+----|
| Pair | dT | dS |
|------+----+----|
| AD | 3 | 3 |
| AF | 4 | 3 |
| AG | 5 | 2 |
| AV | 4 | 3 |
| DF | 3 | 3 |
| DG | 2 | 1 |
| DV | 3 | 2 |
| FG | 1 | 4 |
| FV | 2 | 2 |
| GV | 3 | 3 |
|------+----+----|
|------+----+----|
| Pair | dT | dS |
|------+----+----|
| CE | 7 | 4 |
| CL | 4 | 3 |
| CN | 4 | 2 |
| CU | 5 | 2 |
| EL | 5 | 3 |
| EN | 3 | 2 |
| EU | 4 | 2 |
| LN | 4 | 4 |
| LU | 3 | 3 |
| NU | 3 | 2 |
|------+----+----|
For six letters, CELNOU is faster to transmit than ADFGVX. It has a minimum time distance separation of 3 and a minimum symbol distance 2.
Time spread
This is an update in response to a comment that suggested instead of minimizing transmission time of a set of letters, you might want to pick letters that are most similar in transmission time. It takes much longer to transmit C (-.-.) than E (.), and this could make CELNU harder to transcribe than ADFGV.
So I went back to the script I’m using and added time spread, the maximum transmission time minus the minimum transmission time, as a criterion. The ADFGV set has a spread of 4 because V takes 4 time units longer to transmit than A. CELNU has a spread of 10.
There are 210 choices of 5 letters that have time distance greater than 1, symbol distance greater than 1, and spread equal to 4. That is, these candidates are more distinct than ADFGV and have the same spread.
It takes 44 time units to transmit ADFGV. Twelve of the 210 candidates identified above require 42 or 40 time units. There are five that take 40 time units:
- ABLNU
- ABNUV
- AGLNU
- AGNUV
- ALNUV
Looking at sets of six letters, there are 464 candidates that have better separation than ADFGVX and equal time spread. One of these, AGLNUX, is an extension of one of the 5-letter candidates above.
The best 6-letter are ABLNUV and AGLNUV. They are better than ADFGVX by all the criteria discussed above. They both have time distance separation 2 (compared to 1), symbol distance separation 2 (compared to 1), time spread 4, (compared to 6) and transmission time 50 (compared to 56).
More Morse code posts





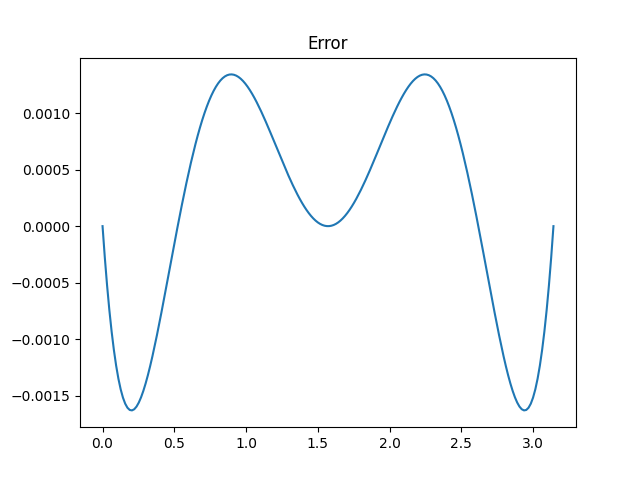 I said that Aryabhata’s approximation is “not quite optimal since the ripples in the error function are not of equal height.” This was an allusion to the equioscillation theorem.
I said that Aryabhata’s approximation is “not quite optimal since the ripples in the error function are not of equal height.” This was an allusion to the equioscillation theorem.