Last week I wrote about how the English seed phrase words for crypto wallets, proposed in BIP39, are not ideal for memorization. This post gives a few more brief thoughts based on these words.
Prefix uniqueness
The BIP39 words have a nice property that I didn’t mention: the words are uniquely determined by their first four letters. This means, for example, that you could type in a seed phrase on a phone by typing the first four letters of each word and a wallet interface could fill in the rest of each word.
Incidentally, although the BIP39 words are unique in how they begin, they are not unique in how they end. For example, cross and across are both on the list.
Creating a list
I wondered how hard it would be to come up with a list of 2048 common words that are unique in their first four letters. So I started with Google’s list of 10,000 most common words.
I removed one- and two-letter words, and NSFW words, to try to create a list similar to the BIP39 words. That resulted in a list of 4228 words. You could delete over half of these words and have a list of 2048 words uniquely determined by their first four letters.
Comparing lists
I was curious how many of the BIP39 list of 2048 words were contained in Google’s list of 10,000 most common words. The answer is 1666, or about 81%. (Incidentally, I used comm to answer this.)
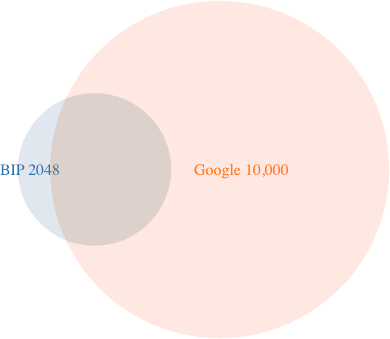
Vocabulary estimation and overlap
Here’s something else I was curious about. The average adult has an active vocabulary of between 20,000 and 35,000 words. So it seems reasonable that a typical adult would know nearly all the words on Google’s top 10,000 list. (Not entirely all. For example, I noticed one word on Google’s list that I hadn’t seen before.)
Now suppose you had a list of the 20,000 most common words and a person with a vocabulary of 20,000 words. How many words on the list is this person likely to know? Surely not all. We don’t acquire our vocabulary by starting at the top of a list of words, ordered by frequency, and working our way down. We learn words somewhat at random according to our circumstances. We’re more likely to know the most common words, but it’s not certain. So how would you model that?
It’s interesting to think how you would estimate someone’s vocabulary in the first place. You can’t give someone a quiz with every English word and ask them to check off the words they know, and estimation complicated by the fact that word frequencies are far from uniform. Maybe the literature on vocabulary estimation would answer the questions in the previous paragraph.








{kind=link}