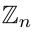This post answers some frequently asked questions regarding my daily tip accounts on Twitter.
How many followers do you have?
About 2800 people are following at least one of these accounts at the time of writing, each following between 2 and 3 accounts on average for a total of about 5900 follows combining all accounts.
How do you schedule your posts?
I schedule the tips a week to a month in advance using HootSuite. Each account posts at the same time each week day starting with SansMouse at 9:30 AM and ending with AlgebraFact at 1:30 PM (US Central Time). Once in a while a tip will go out late due to a Twitter API failure. I occasionally sprinkle in a few unscheduled tweets but I keep the volume low.
What if I don’t use Twitter?
You can subscribe to a Twitter feed via RSS just as you would a blog. For example, you could follow Twitter accounts via Google Reader.
How advanced are these tips?
The SansMouse and RegexTip are in a cycle that starts with the most familiar tips and then moves on to less familiar ones. I mix elementary and advanced material in the mathematical accounts, though there’s a greater range in some accounts. If a tip is more elementary or more advanced than you’d like, you may find something more to your liking in a day or two.
Do you take suggestions? Questions?
I welcome corrections as well as suggestions for new tips. General suggestions are helpful, but I especially appreciate specific tweets.
I like to answer questions when I can, though I can’t respond to every question.
Any plans for new accounts?
I have a couple ideas I’m considering. If you have a suggestion for another daily tip account, let me know.
What about questions about specific accounts?
The following isn’t Q&A format, but it answers some common questions.
 SansMouse is my oldest daily tip account. It gives one Windows keyboard shortcut each day. Most tips apply across all applications, but some tips are specific to popular software packages. Ben Jaffe has an analogous Twitter account commandtab for Mac OS.
SansMouse is my oldest daily tip account. It gives one Windows keyboard shortcut each day. Most tips apply across all applications, but some tips are specific to popular software packages. Ben Jaffe has an analogous Twitter account commandtab for Mac OS.
 RegexTip is currently the second most popular daily tip account with 1025 followers at the time of writing. This account gives tips for writing regular expressions as well as tips for how regular expressions are used in different environments. I mostly stick to the regular expression syntax supported by Perl 5, Microsoft’s .NET languages, JavaScript, etc.
RegexTip is currently the second most popular daily tip account with 1025 followers at the time of writing. This account gives tips for writing regular expressions as well as tips for how regular expressions are used in different environments. I mostly stick to the regular expression syntax supported by Perl 5, Microsoft’s .NET languages, JavaScript, etc.
 TeXtip gives tips for typesetting in TeX and LaTeX. Topics include TeX commands, software for working with LaTeX, tips on typography, etc. I basically stick to LaTeX, though much applies to plain TeX. Also, I don’t say much about add-on packages but stick to the heart of LaTeX.
TeXtip gives tips for typesetting in TeX and LaTeX. Topics include TeX commands, software for working with LaTeX, tips on typography, etc. I basically stick to LaTeX, though much applies to plain TeX. Also, I don’t say much about add-on packages but stick to the heart of LaTeX.
 ProbFact is currently the most popular daily tip account with 1100 followers. This account gives one fact per day from probability. Probability and statistics are intimately related, but this account primarily sticks to probability proper, though some posts are more statistical. People have suggested I start a statistical counterpart to ProbFact, but I have no plans to do so.
ProbFact is currently the most popular daily tip account with 1100 followers. This account gives one fact per day from probability. Probability and statistics are intimately related, but this account primarily sticks to probability proper, though some posts are more statistical. People have suggested I start a statistical counterpart to ProbFact, but I have no plans to do so.
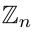 AlgebraFact gives facts from linear algebra, number theory, group theory, etc. A few of the facts are advanced but most are not. I’ve gotten a few complaints for including number theory, but that’s been part of the charter from the beginning. The name AlgebraAndNumberTheoryFact would be more accurate, but too long.
AlgebraFact gives facts from linear algebra, number theory, group theory, etc. A few of the facts are advanced but most are not. I’ve gotten a few complaints for including number theory, but that’s been part of the charter from the beginning. The name AlgebraAndNumberTheoryFact would be more accurate, but too long.
 TopologyFact gives theorems from topology (point-set topology, algebraic topology, etc.) and geometry. Point-set topology has a lot of theorems that can be condensed into 140 characters but I find other areas harder to tweet about. I could use some help here. I’d like to include more geometry: Euclidean geometry, differential geometry, etc. But I don’t want to include material so esoteric that not many will understand it.
TopologyFact gives theorems from topology (point-set topology, algebraic topology, etc.) and geometry. Point-set topology has a lot of theorems that can be condensed into 140 characters but I find other areas harder to tweet about. I could use some help here. I’d like to include more geometry: Euclidean geometry, differential geometry, etc. But I don’t want to include material so esoteric that not many will understand it.
 AnalysisFact is the most advanced account on average. Some of the posts are elementary, but some fairly advanced. Topics include real and complex analysis, functional analysis, special functions, differential equations, etc.
AnalysisFact is the most advanced account on average. Some of the posts are elementary, but some fairly advanced. Topics include real and complex analysis, functional analysis, special functions, differential equations, etc.
I’m doing a drawing to give away either a coffee mug or T-shirt to someone who mentions these tips on Twitter. Tomorrow is the last day to enter.
 I also have a personal Twitter account. I use this account to post links, interact with friends, etc. I try to keep the signal to noise ratio fairly high, though not as high as the tip accounts.
I also have a personal Twitter account. I use this account to post links, interact with friends, etc. I try to keep the signal to noise ratio fairly high, though not as high as the tip accounts.


 SansMouse is my oldest daily tip account. It gives one Windows keyboard shortcut each day. Most tips apply across all applications, but some tips are specific to popular software packages. Ben Jaffe has an analogous Twitter account
SansMouse is my oldest daily tip account. It gives one Windows keyboard shortcut each day. Most tips apply across all applications, but some tips are specific to popular software packages. Ben Jaffe has an analogous Twitter account