Robert Bosch has a new book coming out next week titled OPT ART: From Mathematical Optimization to Visual Design. This post will look at just one example from the book: creating images of Frankenstein’s monster [1] using dominoes.

The book includes two images, a low-resolution image made from 3 sets of dominoes and a high resolution image made from 48 sets. These are double nine dominoes rather than the more common double six dominoes because the former allow a more symmetric arrangement of dots. There are 55 dominoes in a double nine set. (Explanation and generalization here.)
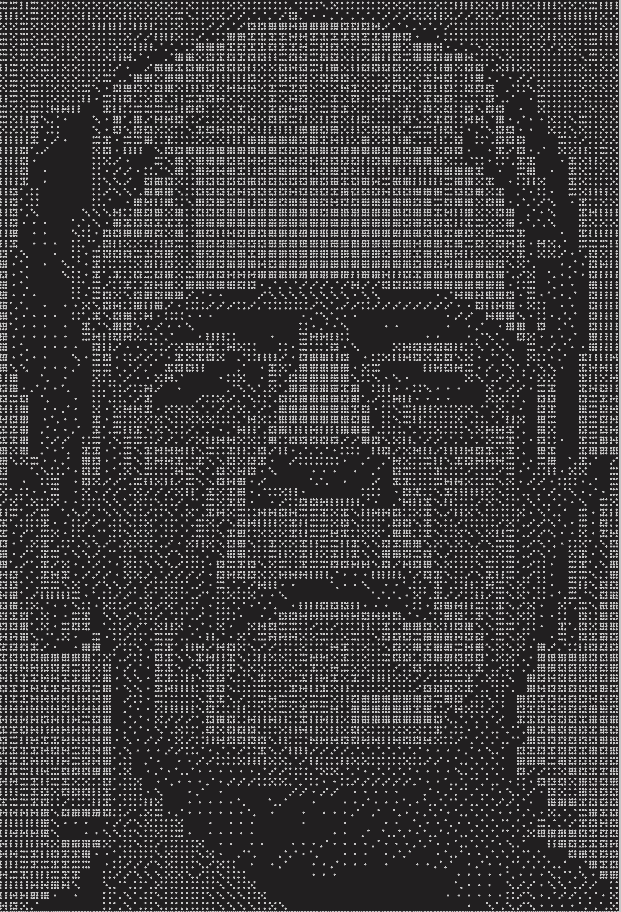
The images are created by solving a constrained optimization problem. You basically want to use dominoes whose brightness is proportional to the brightness of the corresponding section of a photograph. But you can only use the dominoes you have, and you have to use them all.
You would naturally want to use double nines for the brightest areas since they have the most white spots and double blanks for the darkest areas. But you only have three of each in the first image, forty eight of each in the second, and you have to make do with the rest of the available pieces. So you solve an optimization problem to do the best you can.
Each domino can be places horizontally or vertically, as long as they fit the overall shape of the image. In the first image, you can see the orientation of the pieces if you look closely. Here’s a little piece from the top let corner.

One double six is placed vertically in the top left. Next to it are another double six and a double five placed horizontally, etc.
There are additional constraints on the optimization problem related to contrast. You don’t just want to match the brightness of the photograph as well as you can, you also want to maintain contrast. For example, maybe a five-two domino would match the brightness of a couple adjacent squares in the photograph, but a seven-one would do a better job of making a distinction between contrasting regions of the image.
Bosch explains that the problem statement for the image using three sets of dominoes required 34,265 variables and 385 domino constraints. It was solved using 29,242 iterations of a simplex algorithm and required a little less than 2 seconds.
The optimization problem for the image created from 48 sets of dominoes required 572,660 variables and 5,335 constraints. The solution required 30,861 iterations of a simplex algorithm and just under one minute of computation.

Related posts
[1] In the Shelley’s novel Frankenstein, the doctor who creates the monster is Victor Frankenstein. The creature is commonly called Frankenstein, but strictly speaking that’s not his name. There’s a quote—I haven’t been able to track down its source—that says “Knowledge is knowing that Frankenstein wasn’t the monster. Wisdom is knowing that Frankenstein was the monster.” That is, the monster’s name wasn’t Frankenstein, but what Victor Frankenstein did was monstrous.
