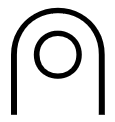
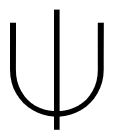
The previous post concerned finding the inverse of a function with respect to Dirichlet convolution. Given a function f defined on the positive integers, we want to find a function g, also defined on positive integers, such that f*g = δ. This means we want to find a function g such that the sum
![]()
evaluates to 1 if n = 1 and 0 otherwise.
We said in that post that the function g can be defined recursively by
![]()
and

for n > 1.
Python code
We can implement this directly in Python as a recursive function. Starting with any function f, we can define g exactly as above. For simplicity we set f(n) = n in the code below.
from sympy import divisors
def f(n):
return n
def g(n):
if n == 1:
return 1/f(1)
s = sum(f(d)*g(n//d) for d in divisors(n)[1:])
return -s/f(1)
The function sympy.divisors returns a list of divisors of a number, sorted in increasing order. We use [1:] to exclude the 0th divisor, i.e. 1, to get the list of divisors greater than 1. The code terminates because d > 1, and so n/d < n.
Note that the code uses integer division in g(n//d). Since we’re dividing n by one of its divisors, n/d is (mathematically) an integer, but the Python code n/d would return a value of type float and cause Python to complain that an argument to g is not an integer.
What’s interesting about this recursion is the set of cases g is defined by. Often a recursive function of n is defined in terms of its value at n-1, as in factorial, or its values at consecutive previous values, as in Fibonacci numbers. But here the value of g at n depends on the the values of g at factors of n.
So, for example, if we evaluate g(12), the code will evaluate g at 1, 2, 3, 4, and 6. In the process of computing g(12) we don’t need to know the value of g at 11.
Caching
Note that there’s some redundancy in the execution of our code. When we evaluate g at 4, for example, it evaluates g at 2, which had already been calculated. We could eliminate this redundancy by using memoization to cache computed values. In Python this can be done with the lru_cache decorator from functools.
import functools
@functools.lru_cache(maxsize=None)
def g(n):
if n == 1:
return 1/f(1)
s = sum(f(d)*g(n//d) for d in divisors(n)[1:])
return -s/f(1)
If we use the revised code to calculate g(12), the call to g(6), for example, will look up the previously computed values of g(1), g(2), and g(3) from a cache.
If we evaluate g at several values, the code will fill in its cache in a scattered sort of way. If our first call is to evaluate g(12), then after that call the values of g at 1, 2, 3, 4, and 6 will be cached, but there will be no value of g at 7, for example, in the cache. If we then evaluate g(7), then this value will be cached, but there’s no value of g at 5 in the cache, and there won’t be until after we evaluate g at a multiple of 5.
Run time
Suppose the cache contains g(x) for all x < n and you want to compute g(n). How long would that take?
For large n, the number of divisors of n is on average about log(n), so the algorithm requires O(log n) look ups. For more detail, see the Dirichlet divisor problem. If you wanted to be more detailed in your accounting, you’d need to take into account the time required to produce the list of n‘s divisors, and the time required to look up cached values. But as a first approximation, the algorithm runs in O(log n) time.
I think the same is true even if you start with an empty cache. It would take longer in this case, but I think this would only change the size of the constant in front of log n.