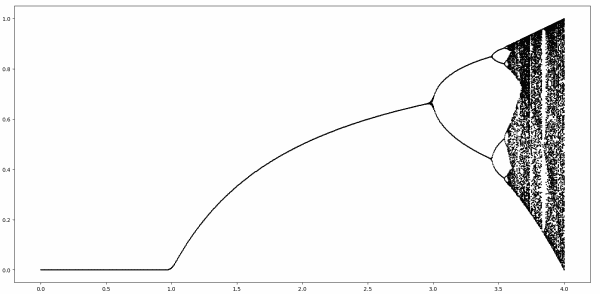
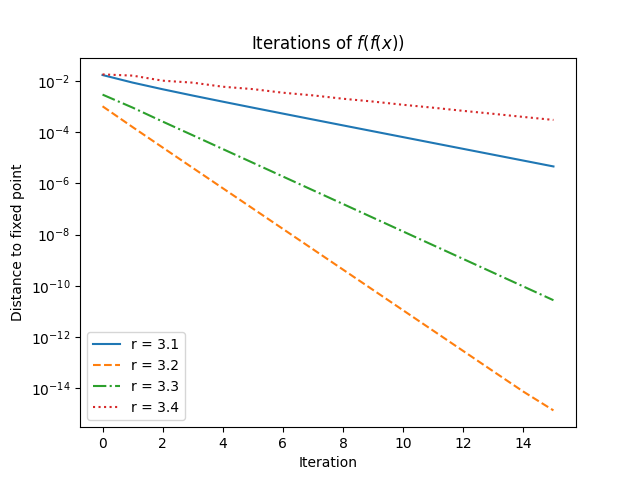
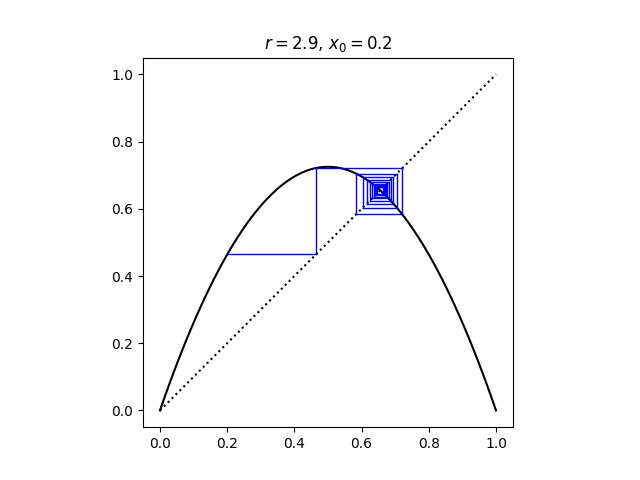
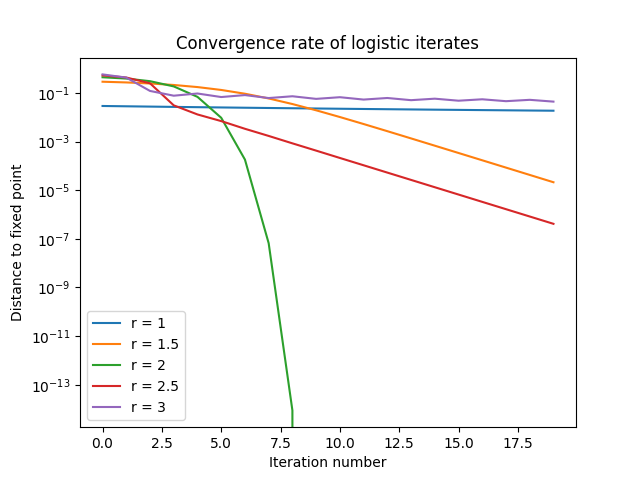
The last four post have looked at the bifurcation diagram for the logistic map.
There was one post on the leftmost region, where there is no branching. Then two posts on the region in the middle where there is period doubling. Then a post about the chaotic region in the end.
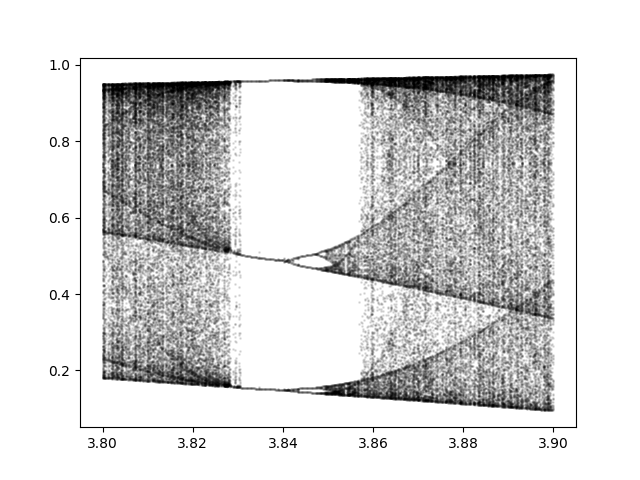
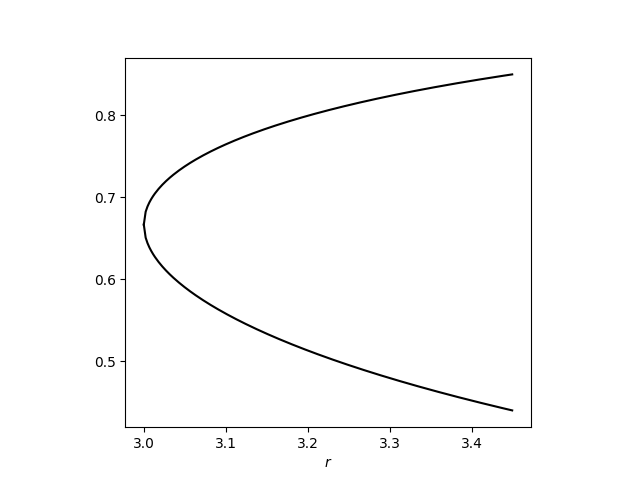
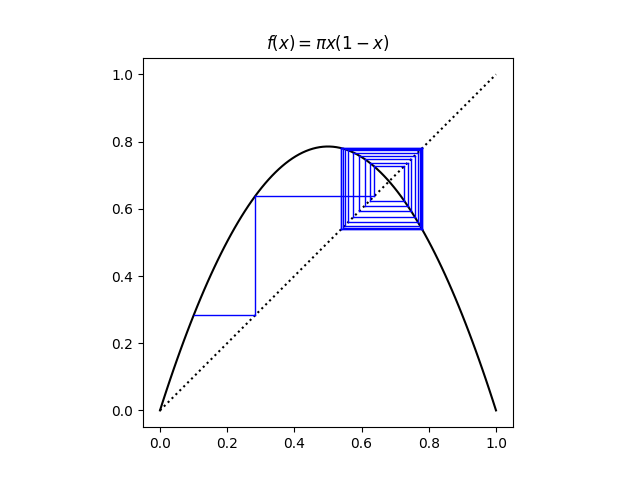
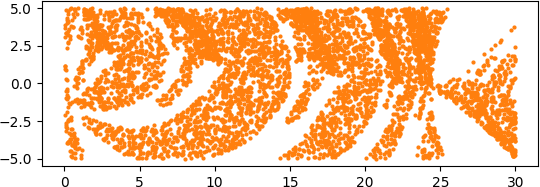
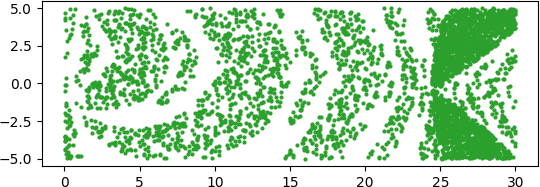
This post returns the middle region. Here’s an image zooming in on the first three forks.
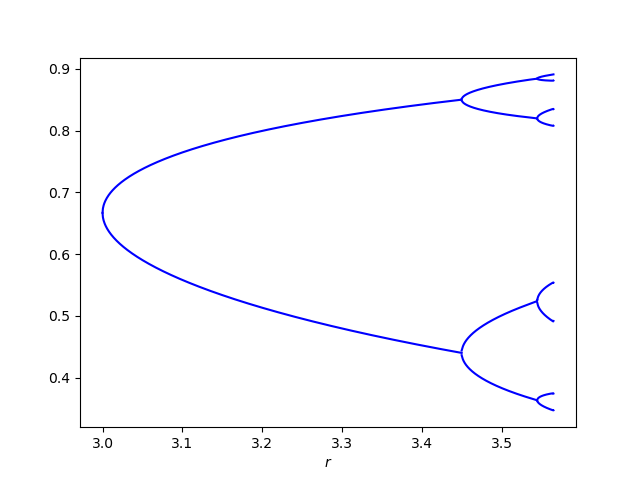
The nth region in the period doubling region has period 2n.
I believe, based on empirical results, that in each branching region, the branches are visited in the same order. For example, in the region containing r = 3.5 there are four branches. If we number these from bottom to top, starting with for the lowest branch, I believe a point on branch 0 will go to a point on branch 2, then branch 1, then branch 3. In summary, the cycle order is [0, 2, 1, 3].
Here are the cycle orders for the next three regions.
[0, 4, 6, 2, 1, 5, 3, 7]
[0, 8, 12, 4, 6, 14, 10, 2, 1, 9, 13, 5, 3, 11, 7, 15]
[0, 16, 24, 8, 12, 28, 20, 4, 6, 22, 30, 14, 10, 26, 18, 2, 1, 17, 25, 9, 13, 29, 21, 5, 3, 19, 27, 11, 7, 23, 15, 31]
[0, 32, 48, 16, 24, 56, 40, 8, 12, 44, 60, 28, 20, 52, 36, 4, 6, 38, 54, 22, 30, 62, 46, 14, 10, 42, 58, 26, 18, 50, 34, 2, 1, 33, 49, 17, 25, 57, 41, 9, 13, 45, 61, 29, 21, 53, 37, 5, 3, 35, 51, 19, 27, 59, 43, 11, 7, 39, 55, 23, 15, 47, 31, 63]
Two questions:
- Is the cycle order constant within a region of a constant period?
- If so, what can be said about the order in general?
I did a little searching into these questions, and one source said there are no known results along these lines. That may or may not be true, but it suggests these are not common questions.