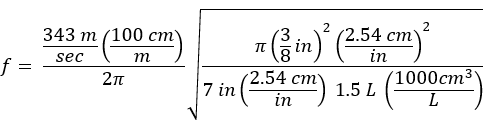I’ve heard that barbershop quartets often sing the 7th in a dominant 7th a little flat in order to bring the note closer in tune with the overtone series. This post will quantify that assertion.
The overtones of a frequency f are 2f, 3f, 4f, 5f, etc. The overtone series is a Fourier series.
Here’s a rendering of the C below middle C and its overtones.

We perceive sound on a logarithmic scale. So although the overtone frequencies are evenly spaced, they sound like they’re getting closer together.
Overtones and equal temperament
Let’s look at the notes in the chord above and compare the frequencies between the overtone series and equal temperament tuning.
Let f be the frequency of the lowest note. The top four notes in this overtone series have frequencies 4f, 5f, 6f, and 7f. They form a C7 chord [1].
In equal temperament, these four notes have frequencies 224/12 f, 228/12 f, 231/12 f, and 234/12 f. This works out to 4, 5.0397, 5.9932, and 7.1272 times the fundamental frequency f
The the highest note, the B♭, is the furthest from its overtone counterpart. The frequency is higher than that of the corresponding overtone, so you’d need to perform it a little flatter to bring it in line with the overtone series. This is consistent with the claim at the top of the post.
Differences in cents
How far apart are 7f and 7.1272f in terms of cents, 100ths of a semitone?
The difference between two frequencies, f1 and f2, measured in cents is
1200 log2(f1 / f2).
To verify this, note that this says an octave equals 1200 cents, because log2 2 = 1.
So the difference between the B♭ in equal temperament and in the 7th note of the overtone series is 31 cents.
The difference between the E and the 5th overtone is 14 cents, and the difference between the G and the 6th overtone is only 2 cents.
More music posts
[1] The dominant 7th chord gets its name from two thing. First, it’s called “dominant” because it’s often found on the dominant (i.e. V) chord of a scale, and it’s made from the 1st, 3rd, 5th, and 7th notes of the scale. It’s a coincidence in the example above that the 7th of the chord is also the 7th overtone. These are two different uses of the number 7 that happen to coincide.