There are four manmade object that have left our solar system: Pioneer 10, Pioneer 11, Voyager 1, and Voyager 2.
Yesterday I wrote about the Golden Record which is on both of the Voyager probes. Some of the graphics on the cover of the Golden Record is also on plaques attached to the Pioneer probes. In particular, the two plaques and the two record covers have the following image.

This image is essential to decoding the rest of the images. It represents a “spin flip transition” of a neutral hydrogen atom. This event has a frequency of 1420.405 MHz, corresponding to a wavelength of about 21 cm. The little hash mark is meant to indicate that this is a unit of measurement, both of length (21 cm) and time (the time it takes light to travel 21 cm).
The thought behind the unit of measurement was that it might make sense to an extraterrestrial being. Frequencies associated with hydrogen atoms are more universal than seconds (which ultimately derive from the period of Earth’s rotation) or meters (which derive from the circumference of the Earth).
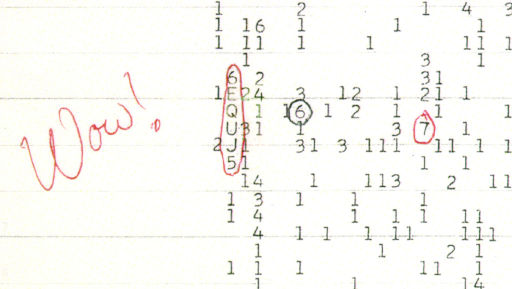
The Wow! signal
The frequency 1420 MHz is special, so special that scientists believed advanced civilizations would recognize it. That’s why an astronomer, Jerry R. Ehman, was excited to observe a strong signal at that frequency on August 15, 1977. (Incidentally, this was five days before Voyager 2 was launched.)
Ehman wrote “Wow!” on a computer printout of the signal, and the signal has become known as “the Wow! signal.”
Ehman thought this signal might have come from an extraterrestrial intelligence for the same reason we were using its frequency in our message to potential extraterrestrials.