The previous post introduced the idea of a twelve-tone row, a permutation of the twelve pitch classes of a chromatic scale.
The earlier post also introduced a group of operations on a tone row with elements P, R, I, and RI. Here P, which stands for “prime”, is the identity operator: it leaves the tone row alone. R stands for retrograde, which means to reverse the sequence. I stands for inversion, inverting each of the intervals in the row. If you apply R then I, you get the same result as if you first applied I then R. See the previous post for an example of each.
Do these operations always return a new tone row? In other words, are P(t), R(t), I(t), and RI(t) always distinct for all tone rows t?
It’s easy to see that P(t) and R(t) are always different. The first and last elements of t are different, and so the first element of P(t) does not equal the first element of R(t).
There is one interval that remains the same when inverted, namely the tritone. It’s possible to create a two-tone row that does not change under inversion, such as the sequence [B, F]. A tone row with more than two notes must have an interval that is not a tritone, and so inverting the tone row changes it.
If a tone row t has at least three notes, then P(t), R(t), I(t), and RI(t) are all distinct.
The pitch classes in a tone row are repeated in a cycle, so we might consider all rotations of a tone row to be in a sense the same. In mathematical terms, we can mod out by cyclic permutations.
If we apply R, I, and RI to equivalence classes of tone rows, the results are not always unique. For example, let t be the chromatic scale.
C C♯ D D♯ E F F♯ G G♯ A A♯ B
Then R(t) is
B A♯ A G♯ G F♯ F E D♯ D C♯ C
and I(t) is
C B A♯ A G♯ G F♯ F E D♯ D C♯
which is a rotation of R(t).
The chromatic scale is a boring tone row. For a random tone row t, all the variations P(t), R(t), I(t), and RI(t) will very likely be distinct, including rotations. The following Python code will illustrate the points above and estimate the probability that manipulations of a tone row are distinct even when equating rotations.
import random
import itertools
def inversion(x, m = 12):
return [(2*x[0] - x[i]) % m for i in range(m)]
def rotate_left(x, n):
return x[n:] + x[:n]
def rotdiff(x, y):
for i in range(len(x)):
if rotate_left(x, i) == y:
return False
return True
c = 0
for _ in range(1_000_000):
P = list(range(12))
random.shuffle(P) # shuffle in place
R = list(reversed(P))
I = list(inversion(P))
RI = list(reversed(I))
for pair in combinations([P, R, I, RI], 2):
assert(pair[0] != pair[1])
if not rotdiff(pair[0], pair[1]):
c += 1
print(c)
This generates and tests a million random tone rows. When I ran it, it found 226 tone rows were one manipulation of the tone row was equal to a rotation of another. So when I said the variations are “very likely” to be distinct, you could quantify that as having over a 99.9% chance.









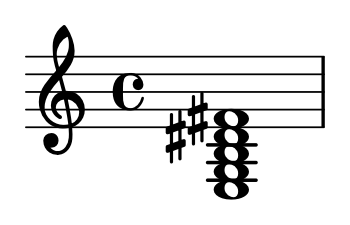

{kind=link}
{kind=link}