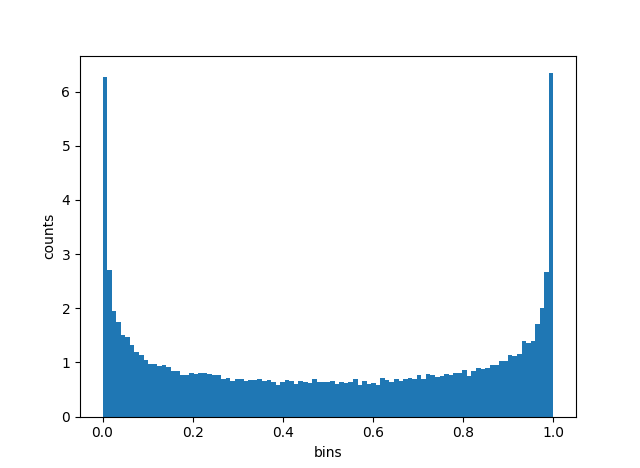
The first digit of a power of 2 is a 1 more often than any other digit. Powers of 2 begin with 1 about 30% of the time. This is because powers of 2 follow Benford’s law. We’ll prove this below.
When is the first digit of 2n equal to k? When 2n is between k × 10p and (k + 1) × 10p for some positive integer p. By taking logarithms base 10 we find that this is equivalent to the fractional part of n log102 being between log10 k and log10 (k + 1).
The map
x ↦ ( x + log10 2 ) mod 1
is ergodic. I wrote about irrational rotations a few weeks ago, and this is essentially the same thing. You could scale x by 2π and think of it as rotations on a circle instead of arithmetic mod 1 on an interval. The important thing is that log10 2 is irrational.
Repeatedly multiplying by 2 is corresponds to adding log10 2 on the log scale. So powers of two correspond to iterates of the map above, starting with x = 0. Birkhoff’s Ergodic Theorem tells us that the number of times iterates of this map fall in the interval [a, b] equals b – a. So for k = 1, 2, 3, … 9, the proportion of powers of 2 start with k is equal to log10 (k + 1) – log10 (k) = log10 ((k + 1) / k).
This is Benford’s law. In particular, the proportion of powers of 2 that begin with 1 is equal to log10 (2) = 0.301.
Note that the only thing special about 2 is that log10 2 is irrational. Powers of 3 follow Benford’s law as well because log10 3 is also irrational. For what values of b do powers of b not follow Benford’s law? Those with log10 b rational, i.e. powers of 10. Obviously powers of 10 don’t follow Benford’s law because their first digit is always 1!
[Interpret the “!” above as factorial or exclamation as you wish.]
Let’s look at powers of 2 empirically to see Benford’s law in practice. Here’s a simple Python program to look at first digits of powers of 2.
count = [0]*10
N = 10000
def first_digit(n):
return int(str(n)[0])
for i in range(N):
n = first_digit( 2**i )
count[n] += 1
print(count)
Unfortunately this only works for moderate values of N. It ran in under a second with N set to 10,000 but for larger values of N it rapidly becomes impractical.
Here’s a much more efficient version that ran in about 2 seconds with N = 1,000,000.
from math import log10
N = 1000000
count = [0]*10
def first_digit_2_exp_e(e):
r = (log10(2.0)*e) % 1
for i in range(2, 11):
if r < log10(i):
return i-1
for i in range(N):
n = first_digit_2_exp_e( i )
count[n] += 1
print(count)
You could make it more efficient by caching the values of log10 rather than recomputing them. This brought the run time down to about 1.4 seconds. That’s a nice improvement, but nothing like the orders of magnitude improvement from changing algorithms.
Here are the results comparing the actual counts to the predictions of Benford’s law (rounded to the nearest integer).
|---------------+--------+-----------|
| Leading digit | Actual | Predicted |
|---------------+--------+-----------|
| 1 | 301030 | 301030 |
| 2 | 176093 | 176091 |
| 3 | 124937 | 124939 |
| 4 | 96911 | 96910 |
| 5 | 79182 | 79181 |
| 6 | 66947 | 66948 |
| 7 | 57990 | 57992 |
| 8 | 51154 | 51153 |
| 9 | 45756 | 45757 |
|---------------+--------+-----------|
The agreement is almost too good to believe, never off by more than 2.
Are the results correct? The inefficient version relied on integer arithmetic and so would be exact. The efficient version relies on floating point and so it’s conceivable that limits of precision caused a leading digit to be calculated incorrectly, but I doubt that happened. Floating point is precise to about 15 significant figures. We start with log10(2), multiply it by numbers up to 1,000,000 and take the fractional part. The result is good to around 9 significant figures, enough to correctly calculate which log digits the result falls between.
Update: See Andrew Dalke’s Python script in the comments. He shows a way to efficiently use integer arithmetic.
Related: Benford’s law posts sorted by application area