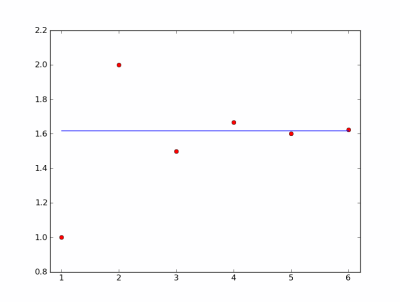
After I finished an electromagnetism course in college, I said that one day I’d go back and really understand the subject. Now I’m starting to do that. I want to understand theory and practical applications, from Maxwell’s equations to Radio Shack.
I’m starting by reading the Feynman lectures on E&M. After that I plan to read something on electronics. If you have resources you recommend, please let me know.
I’ve started new Twitter account, @GrokEM. I figure that tweeting about E&M will help me stick to my goal. My other Twitter accounts post on a regular schedule (plus a few extras) and are scheduled weeks in advance. GrokEM will be more erratic, at least for now. (In case you’re not familiar with grok, it’s a slang for knowing something thoroughly and intuitively.)
[Update: GrokEM has become ScienceTip and is about more than E&M.]
Here’s what Feynman said about mathematicians learning physics, particularly E&M.
Mathematicians, or people who have very mathematical minds, are often led astray when “studying” physics because they loose sight of the physics. They say: “Look, these differential equations — the Maxwell equations — are all there is to electrodynamics … if I understand them mathematically inside out, I will understand the physics inside out.” Only it doesn’t work that way. … They fail because the actual physical situations in the real world are so complicated that it is necessary to have a much broader understanding of the equations. … A physical understanding is a completely unmathematical, imprecise, and inexact thing, but absolutely necessary for a physicist.
Heinlein coined grok around the same time that Feynman made the above remarks. Otherwise, Feynman might have said that only studying differential equations is not the way to grok electrodynamics.