This afternoon I was working on a project involving tonal prominence. I stepped away from the computer to think and was interrupted by the sound of a leaf blower. I was annoyed for a second, then I thought “Hey, a leaf blower!” and went out to record it. A leaf blower is a great example of a broad spectrum noise with strong tonal components. Lawn maintenance men think you’re kinda crazy when you say you want to record the noise of their equipment.
The tuner app on my phone identified the sound as an A3, the A below middle C, or 220 Hz. Apparently leaf blowers are tenors.
Here’s a short audio clip:
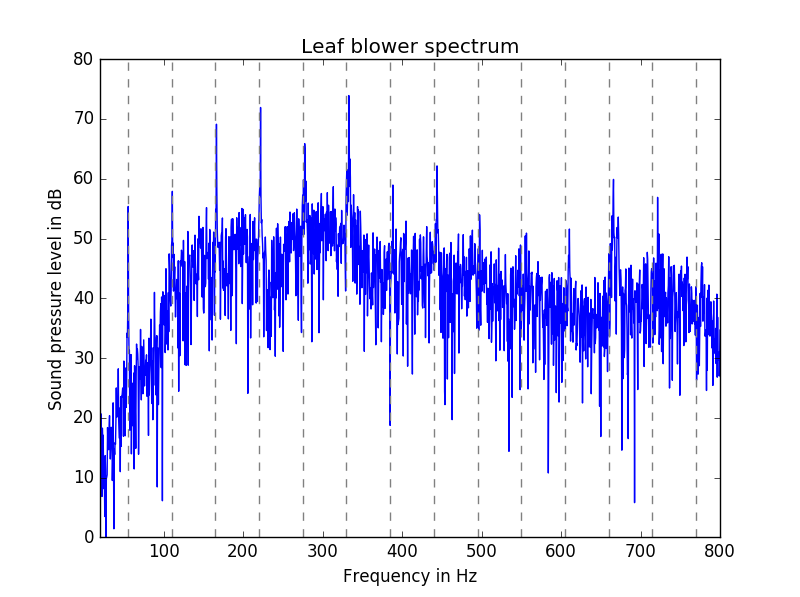
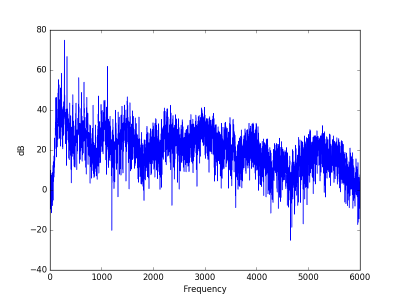
And here’s what the spectrum looks like. The dashed grey vertical lines are at multiples of 55 Hz.
The peaks are perfectly spaced at multiples of the fundamental frequency of 55 Hz, A1 in scientific pitch notation. This even spacing of peaks is the fingerprint of a definite tone. There’s also a lot of random fluctuation between peaks. That’s the finger print of noise. So together we hear a pitch and noise.
When using the tone-to-noise ratio algorithm from the ECMA-74, only the spike at 110 Hz is prominent. A limitation of that approach is that it only considers single tones, not how well multiple tones line up in a harmonic sequence.
This post looks at loudness and sharpness, two important psychoacoustic metrics. Because they have to do with human perception, these factors are by definition subjective. And yet they’re not entirely subjective. People tend to agree on when, for example, one sound is twice as loud as another, or when one sound is sharper than another.
Loudness
Loudness is the psychological counterpart to sound pressure level. Sound pressure level is a physical quantity, but loudness is a psychoacoustic quantity. The former has to do with how a microphone perceives sound, the latter how a human perceives sound. Sound pressure level in dB and loudness in phon are roughly the same for a pure tone of 1 kHz. But loudness depends on the power spectrum of a sound and not just it’s sound pressure level. For example, if a sound’s frequency is too high or too low to hear, it’s not loud at all! See my previous post on loudness for more background.
Let’s take the four guitar sounds from the previous post and scale them so that each has a sound pressure level of 65 dB, about the sound level of an office conversation, then rescale so the sound pressure is 90 dB, fairly loud though not as loud as a rock concert. [Because sound perception is so nonlinear, amplifying a sound does not increase the loudness or sharpness of every component equally.]
While all four sounds have the same sound pressure level, the undistorted sounds have the lowest loudness. The distorted sounds are louder, especially the single note. Increasing the sound pressure level from 65 dB to 90 dB increases the loudness of each sound by roughly the same amount. This will not be true of sharpness.
Sharpness
Sharpness is related how much a sound’s spectrum is in the high end. You can compute sharpness as a particular weighted sum of the specific loudness levels in various bands, typically 1/3-octave bands. This weight function that increases rapidly toward the highest frequency bands. For more details, see Psychoacoustics: Facts and Models.
The table below gives sharpness, measured in acum, for the four guitar sounds at 65 dB and 90 dB.
Although a clean chord sounds a little louder than a single note, the former is a little sharper. Distortion increases sharpness as it does loudness. The single note with distortion is a little louder than the other sounds, but much sharper than the others.
Notice that increasing the sound pressure level increases the sharpness of the sounds by different amounts. The sharpness of the last sound hardly changes.
The other day I asked on Google+ if someone could make an audio clip for me and Dave Jacoby graciously volunteered. I wanted a simple chord on an electric guitar played with varying levels of distortion. Dave describes the process of making the recording as
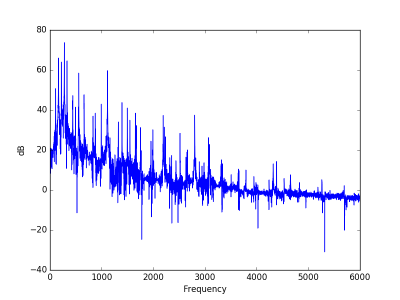
Let’s look at the Fourier spectrum at four places in the recording: single note and chord, clean and distorted. These are a 0:02, 0:08, 0:39, and 0:43.
Power spectra
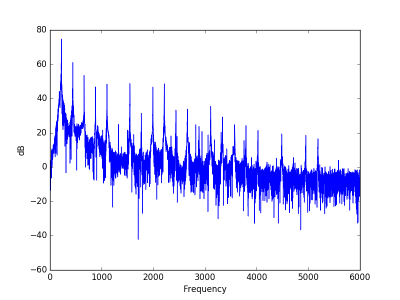
The first note, without distortion, has most of its spectrum concentrated at 220 Hz, the A below middle C.
The same note with distortion has a power spectrum that decays much slow, i.e. the sound has more high frequency components.
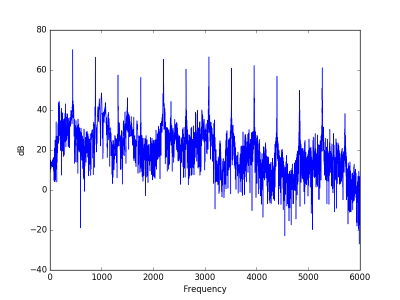
Here’s the A major chord without distortion. Note that since the threshold of hearing is around 20 dB, most of the noise components are inaudible.
Here’s the same chord with distortion. Notice there’s much more noise in the audible range.
Update: See the next post an analysis of the loudness and sharpness of the audio samples in this post.
Kettledrums (a.k.a. tympani) produce a definite pitch, but in theory they should not. At least the simplest mathematical model of a kettledrum would not have a definite pitch. Of course there are more accurate theories that align with reality.
Unlike many things that work in theory but not in practice, kettledrums work in practice but not in theory.
A musical sound has a definite pitch when the first several Fourier components are small integer multiples of the lowest component, the fundamental. A pitch we hear at 100 Hz would have a first overtone at 200 Hz, the second at 300 Hz, etc. It’s the relative strengths of these components give each instrument its characteristic sound.
An ideal string would make a definite pitch when you pluck it. The features of a real string discarded for the theoretical simplicity, such as stiffness, don’t make a huge difference to the tonality of the string.
An ideal circular membrane would vibrate at frequencies that are much closer together than consecutive integer multiples of the fundamental. The first few frequencies would be at 1.594, 2.136, 2.296, 2.653, and 2.918 times the fundamental. Here’s what that would sound like:
I chose amplitudes of 1, 1/2, 1/3, 1/4, 1/5, and 1/6. This was somewhat arbitrary, but not unrealistic. Including more than the first six Fourier components would make the sound even more muddled.
By comparison, here’s what it would sound like with the components at 2x up to 6x the fundamental, using the same amplitudes.
This isn’t an accurate simulation of tympani sounds, just something simple but more realistic than the vibrations of an idea membrane.
The real world complications of a kettledrum spread out its Fourier components to make it have a more definite pitch. These include the weight of air on top of the drum, the stiffness of the drum head, the air trapped in the body of the drum, etc.
If you’d like to read more about how kettle drums work, you might start with The Physics of Kettledrums by Thomas Rossing in Scientific American, November 1982.
What do tuning a guitar and tuning a radio have in common? Both are examples of beats or amplitude modulation.
Examples
In an earlier post I wrote about how beats come up in vibrating systems, such as a mass and spring combination or an electric circuit. Here I look at examples from music and radio.
Music
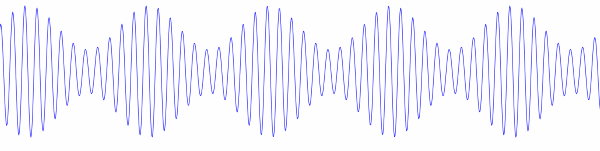
When two musical instruments play nearly the same note, they produce beats. The number of beats per second is the difference in the two frequencies. So if two flutes are playing an A, one playing at 440 Hz and one at 442 Hz, you’ll hear a pitch at 441 Hz that beats two times a second. Here’s a wave file of two pure sine waves at 440 Hz and 442 Hz.
As the players come closer to being in tune, the beats slow down. Sometimes you don’t have two instruments but two strings on the same instrument. Guitarists listen for beats to tell when two strings are playing the same note with the same pitch.
AM radio
The same principle applies to AM radio. A message is transmitted by multiplying a carrier signal by the content you want to broadcast. The beats are the content. As we’ll see below, in some ways the musical example and the AM radio example are opposites. With tuning, we start with two sources and create beats. With AM radio, we start by creating beats, then see that we’ve created two sources, the sidebands of the signal.
Mathematical explanation
Both examples above relate to the following trig identity:
cos(a − b) + cos(a + b) = 2 cos a cos b
And because we’re looking at time-varying signals, slip in a factor of 2πt:
cos(2π(a − b)t) + cos(2π(a + b)t) = 2 cos 2πat cos 2πbt
Music
In the case of two pure tones, slightly out of tune, let a = 441 and b = 1. Playing an A 440 and an A 442 at the same time results in an A 441, twice as loud, with the amplitude going up and down like cos 2πt, i.e. oscillating two times a second. (Why two times and not just once? One beat for the maximum and one for the minimum of cos 2πt.)
It may be hard to hear beats because of complications we’ve glossed over. Musical instruments are never perfectly in phase, but more importantly they’re not pure tones. An oboe, for example, has strong components above the fundamental frequency. I used a flute in this example because although its tone is not simply a sine wave, it’s closer to a sine wave than other instruments, especially when playing higher notes. Also, guitarists often compare the harmonics of two strings. These are purer tones and so it’s easier to hear beats between them.
Radio
For the case of AM radio, read the equation above from right to left. Let a be the frequency of the carrier wave. For example if you’re broadcasting on AM station 700, this means 700 kHz, so a = 700,000. If this station were broadcasting a pure tone at 440 Hz, b would be 440. This would produce sidebands at 700,440 Hz and 699,560 Hz.
In practice, however, the carrier is not multiplied by a signal like cos 2πbt but by 1 + m cos 2πbt where |m| < 1 to avoid over-modulation. Without this extra factor of 1 the signal would be 100% modulated; the envelope of the signal would pinch all the way down to zero. By including the factor of 1 and using a modulation index m less than 1, the signal looks more like the image above, with the envelope not pinching all the way down. (Over-modulation occurs when m > 1. Instead of the envelope pinching to zero, the upper and lower parts of the envelop cross.)
I’ve played saxophone since I was in high school, and I thought I knew how saxophones work, but I learned something new this evening. I was listening to a podcast [1] on musical acoustics and much of it was old hat. Then the host said that a saxophone has two octave holes. Really?! I only thought there was only one.
When you press the octave key on the back of a saxophone with your left thumb, the pitch goes up an octave. Sometimes this causes a key on the neck to open up and sometimes it doesn’t [2]. I knew that much.
I thought that when this key didn’t open, the octaves work like they do on a flute: no mechanical change to the instrument, but a change in the way you play. And to some extent this is right: You can make the pitch go up an octave without using the octave key. However, when the octave key is pressed there is a second hole that opens up when the more visible one on the neck closes.
According to the podcast, the first saxophones had two octave keys to operate with your thumb. You had to choose the correct octave key for the note you’re playing. Modern saxophones work the same as early saxophones except there is only one octave key controlling two octave holes.
* * *
[1] Musical Acoustics from The University of Edinburgh, iTunes U.
[2] On the notes written middle C up to A flat, the octave key raises the little hole I wasn’t aware of. For higher notes the octave key raises the octave hole on the neck.
How can you convert the frequency of a sound to musical notation? I wrote in an earlier post how to calculate how many half steps a frequency is above or below middle C, but it would be useful go further have code to output musical pitch notation.
In scientific pitch notation, the C near the threshold of hearing, around 16 Hz, is called C0. The C an octave higher is C1, the next C2, etc. Octaves begin with C; other notes use the octave number of the closest C below.
The lowest note on a piano is A0, a major sixth up from C0. Middle C is C4 because it’s 4 octaves above C0. The highest note on a piano is C8.
Math
A4, the A above middle C, has a frequency of 440 Hz. This is nine half steps above C4, so the pitch of C4 is 440*2−9/12. C0 is four octaves lower, so it’s 2−4 = 1/16 of the pitch of C4. (Details for this calculation and the one below are given in here.)
For a pitch P, the number of half steps from C0 to P is
h = 12 log2(P / C0).
Software
Here is a page that will let you convert back and forth between frequency and music notation: Music, Hertz, Barks.
If you’d like code rather than just to do one calculation, see the Python code below. It calculates the number of half steps h from C0 up to a pitch, then computes the corresponding pitch notation.
from math import log2, pow
A4 = 440
C0 = A4*pow(2, -4.75)
name = ["C", "C#", "D", "D#", "E", "F", "F#", "G", "G#", "A", "A#", "B"]
def pitch(freq):
h = round(12*log2(freq/C0))
octave = h // 12
n = h % 12
return name[n] + str(octave)
The pitch for A4 is its own variable in case you’d like to modify the code for a different tuning. While 440 is common, it used to be lower in the past, and you’ll sometimes see higher values like 444 today.
If you’d like to port this code to a language that doesn’t have a log2 function, you can use log(x)/log(2) for log2(x).
Powers of 2
When scientific pitch notation was first introduced, C0 was defined to be exactly 16 Hz, whereas now it works out to around 16.35. The advantage of the original system is that all C’s have frequency a power of 2, i.e. Cn has frequency 2n+4 Hz. The formula above for the number of half steps a pitch is above C0 simplifies to
h = 12 log2P − 48.
If C0 has frequency 16 Hz, the A above middle C has frequency 28.75 = 430.54, a little flat compared to A 440. But using the A 440 standard, C0 = 16 Hz is a convenient and fairly accurate approximation.
Every positive integer can be written as the sum of distinct Fibonacci numbers. For example, 10 = 8 + 2, the sum of the fifth Fibonacci number and the second.
This decomposition is unique if you impose the extra requirement that consecutive Fibonacci numbers are not allowed. [1] It’s easy to see that the rule against consecutive Fibonacci numbers is necessary for uniqueness. It’s not as easy to see that the rule is sufficient.
Every Fibonacci number is itself the sum of two consecutive Fibonacci numbers—that’s how they’re defined—so clearly there are at least two ways to write a Fibonacci number as the sum of Fibonacci numbers, either just itself or its two predecessors. In the example above, 8 = 5 + 3 and so you could write 10 as 5 + 3 + 2.
The nth Fibonacci number is approximately φn/√5 where φ = 1.618… is the golden ratio. So you could think of a Fibonacci sum representation for x as roughly a base φ representation for √5x.
You can find the Fibonacci representation of a number x using a greedy algorithm: Subtract the largest Fibonacci number from x that you can, then subtract the largest Fibonacci number you can from the remainder, etc.
Programming exercise: How would you implement a function that finds the largest Fibonacci number less than or equal to its input? Once you have this it’s easy to write a program to find Fibonacci representations.
* * *
[1] This is known as Zeckendorf’s theorem, published by E. Zeckendorf in 1972. However, C. G. Lekkerkerker had published the same result 20 years earlier.
If you hear electrical equipment humming, it’s probably at a pitch of about 60 Hz since that’s the frequency of AC power, at least in North America. In Europe and most of Asia it’s a little lower at 50 Hz. Here’s an audio clip in a couple formats: wav, mp3.
The screen shot above comes from a tuner app taken when I was around some electrical equipment. The pitch sometimes registered at A# and sometimes as B, and for good reason. In a previous post I derived the formula for converting frequencies to musical pitches:
h = 12 log(P / C) / log 2.
Here C is the pitch of middle C, 261.626 Hz, P is the frequency of your tone, and h is the number of half steps your tone is above middle C. When we stick P = 60 Hz into this formula, we get h = −25.49, so our electrical hum is half way between 25 and 26 half-steps below middle C. So that’s between a A# and a B two octaves below middle C.
For 50 Hz hum, h = −28.65. That would be between a G and a G#, a little closer to G.
Update: So why would the frequency of the sound match the frequency of the electricity? The magnetic fields generated by the current would push and pull parts, driving mechanical vibrations at the same frequency.