Suppose you were a contemporary professor sent back in time. You need to continue your academic career, but you can’t let anyone know that you’re from the future. You can’t take anything material with you but you retain your memories.
At first thought you might think you could become a superstar, like the musician in the movie Yesterday who takes credit for songs by The Beatles. But on second thought, maybe not.
Maybe you’re a physicist and you go back in time before relativity. If you go back far enough, people will not be familiar with the problems that relativity solves, and your paper on relativity might not be accepted for publication. And you can’t just post it on arXiv.
If you know about technology that will be developed, but you don’t know how to get there using what’s available in the past, it might not do you much good. Someone with a better knowledge of the time’s technology might have the advantage.
If you’re a mathematician and you go back in time 50 years, could you scoop Andrew Wiles on the proof of Fermat’s Last Theorem? Almost certainly not. You have the slight advantage of knowing the theorem is true, whereas your colleagues only strongly suspect that it’s true. But what about the proof?
If I were in that position, I might think “There’s something about a Seaborn group? No, that’s the Python library. Selmer group? That sounds right, but maybe I’m confusing it with the musical instrument maker. What is this Selmer group anyway, and how does it let you prove FLT?”
Could Andrew Wiles himself reproduce the proof of FTL without access to anything written after 1971? Maybe, but I’m not sure.
In your area of specialization, you might be able to remember enough details of proven results to have a big advantage over your new peers. But your specialization might be in an area that hasn’t been invented yet, and you might know next to nothing about areas of research that are currently in vogue. Maybe you’re a whiz at homological algebra, but that might not be very useful in a time when everyone is publishing papers on differential equations and special functions.
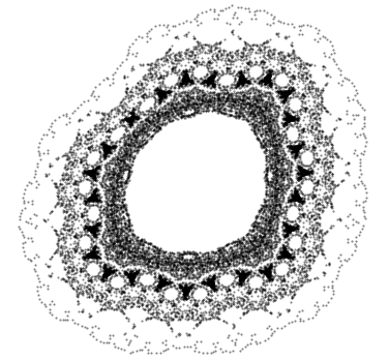
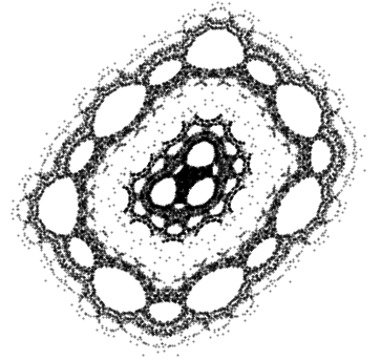
There are a few areas where a time traveler could make a big splash, areas that could easily have been developed much sooner but weren’t. For example, the idea of taking the output of a function and sticking it back in, over and over, is really simple. But nobody looked into it deeply until around 50 years ago.
Then came the Mandelbrot set, Feigenbaum’s constants, period three implies chaos, and all that. A lack of computer hardware would be frustrating, but not insurmountable. Because computers have shown you what phenomena to look for, you could go back and reproduce them by hand.
In most areas, I suspect knowledge of the future wouldn’t be an enormous advantage. It would obviously be some advantage. Knowing which way a conjecture was settled tells you whether to try to prove or disprove it. In the language of microprocessors, it gives you good branch prediction. And it would help to have patterns in your head that have turned out to be useful, even if you couldn’t directly appeal to these patterns without blowing your cover. But I suspect it might make you something like 50% more productive, not enough to turn an average researcher into a superstar.