If you’ve only seen one definition of spherical coordinates, you may be shocked to discover that there are multiple conventions. In particular, mathematicians and geoscientists have different conventions. As Volker Michel put it in book on constructive approximation,
Many mathematicians have faced weird jigsaw puzzles with misplaced continents after using a data set from a geoscientist.
Nor are there only two conventions. This post will cover three conventions, which I will call physics, math, and geography. This is not to imply that everyone in a profession uses the conventions named after the profession.
As with Fourier transforms there are many conventions. Presumably the reason for the proliferation of conventions is the same: a useful basic concept will be discovered multiple times in different areas of application. When there are trade-offs between conventions, people working in each area will choose the convention that is simplest for the things they care most about.
Questions and definitions
Given a triple of numbers (c1, c2, c3), that represent spherical coordinates, there are two basic questions:
- What do the numbers mean?
- What symbol should be used to represent them?
Part of the meaning question is whether the coordinate system is left-handed or right-handed. There is also a minor question of the standard range of equivalent angles.
Polar angle is the angle down from the positive z-axis, the north pole. The north pole has polar angle 0 and the south pole has polar angle π.
Latitude is the angle up from the xy plane or the equator. The latitude of the north pole is π/2 and the latitude of the south pole is −π/2.
Azimuth is the angle from an initial meridian (e.g. the Prime Meridian in geography). In mathematical terms it is the angle between the x-axis and a line connecting the projection of a point to the xy to the origin.
Physics convention
The physics convention is also the ISO 80000-2 convention. The three coordinates are
(radial distance to origin, polar angle, azimuthal angle)
and are conventionally denoted
(r, θ, ϕ).
The point (r, θ, ϕ) corresponds to
(r sin θ cos ϕ, r sin θ sin ϕ, r cos θ)
in Cartesian coordinates.
The coordinate system is right-handed: ϕ increases in the counterclockwise direction when looking down on the xy plane.
The polar angle typically runs from 0 to π and the azimuthal angle typically runs from 0 to 2π.
Math convention
In this convention the three coordinates are
(radial distance to origin, azimuthal angle, polar angle)
and are denoted
(ρ, θ, ϕ).
When compared to the physics notation we have something of a Greek letter paradox. Both conventions agree that the second coordinate should be written θ and the third coordinate should be written ϕ, but the two conventions mean opposite things by the two symbols.
The advantage of using θ to denote the azimuthal angle is that then θ has the same meaning as it has in polar coordinates. Similarly, the advantage of using ρ rather than r is to preserve the meaning of r in polar and cylindrical coordinates: ρ is the distance in 3 dimensions from a point to the origin, and r is the distance in 2 dimensions from the projection of a point to the xy plane and the origin.
Sometimes you’ll see r rather than ρ for the first coordinate.
The point (ρ, θ, ϕ) corresponds to
(ρ cos θ sin ϕ, ρ sin θ sin ϕ, ρ cos ϕ).
The math convention uses the same orientation and typical range coordinate ranges as the physics convention.
Geography and geoscience
Geographic coordinate systems are complicated by the fact that the earth is not perfectly spherical. Geographic latitude and geocentric latitude are not exactly the same as the following highly exaggerated diagram shows.
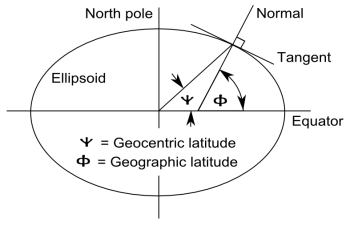
However, for this post we will assume a perfectly spherical earth in which geographic and geocentric latitudes are the same.
A point on the earth’s surface is described by two numbers, latitude and longitude. This corresponds to spherical coordinates in which the first coordinate is implicitly the earth’s radius. You’ll see latitude and longitude listed in either order.
The polar angle is sometimes called colatitude because latitude is the complementary angle of latitude. Longitude corresponds to azimuth. There are multiple symbols used for latitude, though λ is common for longitude. If you see one coordinate denoted λ, the other is latitude.
The safest, most explicit notation is to use the words longitude and latitude, not depending on symbols or order. Longitude is implicitly longitude east of the Prime Meridian, but to be absolutely clear, put an E at the end. Latitude typically ranges from −π/2 to π/2 (−90° to 90°). Longitude either runs from 0 to 2π or from −π to π (−180° to 180°).
To convert to Cartesian coordinates, set polar angle to π/2 − latitude, azimuth to longitude (east), and use the formulas above for either the physics or mathematics notation. If you have elevation, this is the radial distance above the earth’s surface, so ρ is the earth’s radius plus elevation.
Related posts