Define

and

This integral comes up in Bayesian logistic regression with a uniform (improper) prior. We will use this integral to illustrate a simple case of Laplace approximation.
The idea of Laplace approximation is to approximate the integral of a Gaussian-like function by the integral of a (scaled) Gaussian with the same mode and same curvature at the mode. That’s the most common, second order Laplace approximation. More generally, Laplace’s approximation depends on truncating a Taylor series, and truncating after the 2nd order term gives the approximation described above.
Let x0 be the place where f takes on its maximum and let g = log f. Note that g also takes on its maximum at x0 and so its first derivative is zero there. Then the (second order) Laplace approximation has the following derivation.

We can show that

and

It follows that x0 = log (m/n) and the Laplace approximation for I(m, n) reduces to
 .
.
Now let’s compare the Laplace approximation to the exact value of the integral for a few values of m and n. We would expect the Laplace approximation to be more accurate when the integrand is shaped more like the Gaussian density. This happens when m and n are large and when they are more nearly equal. (The function f is a likelihood, and m+n is the number of data points in the likelihood. More data means the likelihood is more nearly normal. Also, m = n means f is symmetric, which improves the normal approximation.)
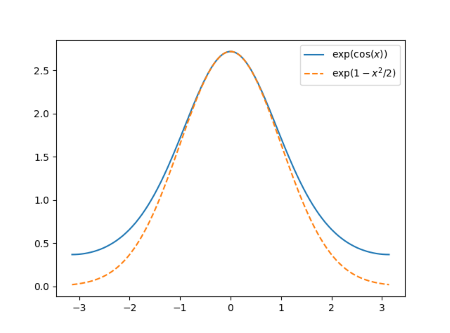
We’ll look at (m, n) = (2, 1), (20, 10), (200, 100), and (15, 15). Here’s the plot of f(x, 2, 1) with its normal approximation, scaled vertically so that the heights match.

Even for small arguments, the Gaussian approximation fits well on the left side, but not so much on the right. For large arguments it would be hard to see the difference between the two curves.
Here are the results of the Laplace approximation and exact integration.
|-----+-----+---------------+---------------+--------------|
| m | n | approx | exact | rel error |
|-----+-----+---------------+---------------+--------------|
| 2 | 1 | 0.45481187 | 0.5 | -0.090376260 |
| 20 | 10 | 4.9442206e-9 | 4.99250870e-9 | -0.009672111 |
| 15 | 15 | 8.5243139e-10 | 8.5956334e-10 | -0.008297178 |
| 200 | 100 | 3.6037801e-84 | 3.6072854e-84 | -0.000971728 |
|-----+-----+---------------+---------------+--------------|
The integrals were computed exactly using Mathematica; the results are rational numbers. [1]
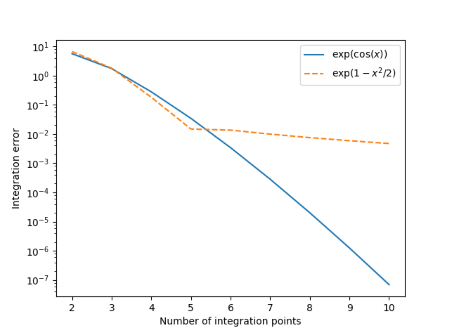
Note that when m and n increase by a factor of 10, the relative error goes down by about a factor of 10. This is in keeping with theory that say the error should be O(1/(m+n)). Also, note that the error for (15, 15) is a little lower than that for (20, 10). The errors are qualitatively just what we expected.
***
[1] I initially used Mathematica to compute the integrals, but then realized that’s not necessary. The change of variables u = exp(x) / (1 + exp(x)) shows that
I(a, b) = B(a, b+1) + B(a+1, b)
where B is the beta function. Incidentally, this shows that if a and b are integers then I(a, b) is rational.
![\frac{1}{\sqrt{2\pi}}\int_{-\infty}^\infty \left(\sum_{k=0}^N a_k\,H_k(x)\right) \exp(-x^2/2) \,dx = \sum_{k=0}^N a_k \, [k\, \mathrm{ even} ] \,k!!](https://www.johndcook.com/hermite_int.svg)





















![E[ f(X) ] \approx \frac{1}{n} \sum_{i=1}^n f(x_i)](http://www.johndcook.com/mcmc.svg)