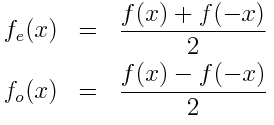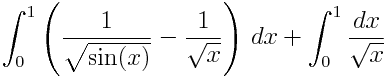Markov Chain Monte Carlo (MCMC) is a technique for getting your work done when Monte Carlo won’t work.
The problem is finding the expected value of f(X) where X is some random variable. If you can draw independent samples xi from X, the solution is simple:
![E[ f(X) ] \approx \frac{1}{n} \sum_{i=1}^n f(x_i)](http://www.johndcook.com/mcmc.svg)
When it’s possible to draw these independent samples, the sum above is well understood. It’s easy to estimate the error after n samples, or to turn it the other way around, estimate what size n you need so that the error is probably below a desired threshold.
MCMC is a way of making the approximation above work even though it’s not practical to draw independent random samples from X. In Bayesian statistics, X is the posterior distribution of your parameters and you want to find the expected value of some function of these parameters. The problem is that this posterior distribution is typically complicated, high-dimensional, and unique to your problem (unless you have a simple conjugate model). You don’t know how to draw independent samples from X, but there are standard ways to construct a Markov chain whose samples make the approximation above work. The samples are not independent but in the limit the set of samples has the same distribution as X.
MCMC is either simple or mysterious, depending on your perspective. It’s simple to write code that should work, eventually, in theory. Writing efficient code is another matter. And above all, knowing when your answer is good enough is tricky. If the samples were independent, the Central Limit Theorem would tell you how the sum should behave. But since the samples are dependent, all bets are off. Almost all we know is that the average on the right side converges to the expectation on the left side. Aside from toy problems there’s very little theory to tell you when your average is sufficiently close to what you want to compute.
Because there’s not much theory, there’s a lot of superstition and folklore. As with other areas, there’s some truth in MCMC superstition and folklore, but also some error and nonsense.
In some ways MCMC is truly marvelous. It’s disappointing that there isn’t more solid theory around convergence, but it lets you take a stab at problems that would be utterly intractable otherwise. In theory you can’t know when it’s time to stop, and in practice you can fool yourself into thinking you’ve seen convergence when you haven’t, such as when you have a bimodal distribution and you’ve only been sampling from one mode. But it’s also common in practice to have some confidence that a calculation has converged because the results are qualitatively correct: this value should be approximately this other value, this should be less than that, etc.
Bayesian statistics is older than Frequentist statistics, but it didn’t take off until statisticians discovered MCMC in the 1980s, after physicists discovered it in the 1950s. Before that time, people might dismiss Bayesian statistics as being interesting but impossible to compute. But thanks to Markov Chain Monte Carlo, and Moore’s law, many problems are numerically tractable that were not before.
Since MCMC gives a universal approach for solving certain kinds of problems, some people equate the algorithm with the problem. That is, they see MCMC as the solution rather than an algorithm to compute the solution. They forget what they were ultimately after. It’s sometimes possible to compute posterior probabilities more quickly and more accurately by other means, such as numerical integration.