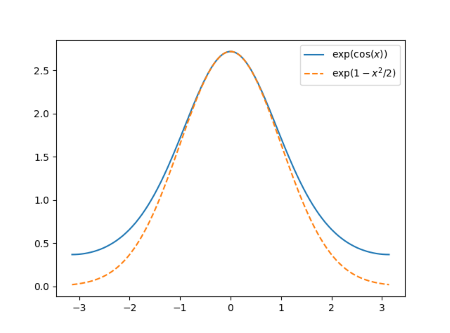
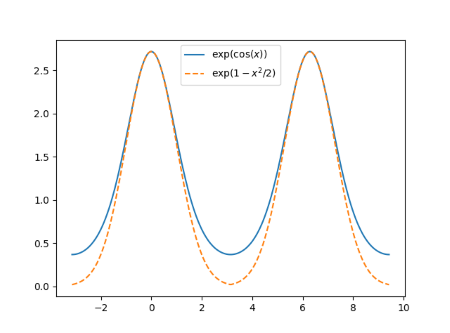
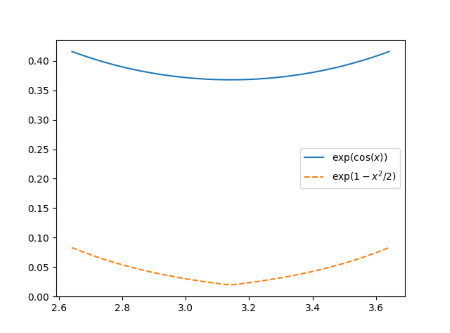
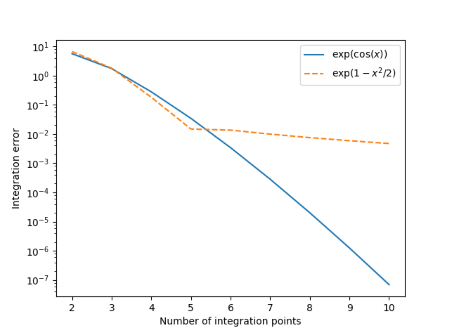
Here’s an apparent paradox. You’ll hear that Monte Carlo methods are independent of dimension, and that they scale poorly with dimension. How can both statements be true?
The most obvious way to compute multiple integrals is to use product methods, analogous to the way you learn to compute multiple integrals by hand. Unfortunately the amount of work necessary with this approach grows exponentially with the number of variables, and so the approach is impractical beyond modest dimensions.
The idea behind Monte Carlo integration, or integration by darts, is to estimate the area under a (high dimensional) surface by taking random points and counting how many fall below the surface. More details here. The error goes down like the reciprocal of the square root of the number of points. The error estimate has nothing to do with the dimension per se. In that sense Monte Carlo integration is indeed independent of dimension, and for that reason is often used for numerical integration in dimensions too high to use product methods.
Suppose you’re trying to estimate what portion of a (high dimensional) box some region takes up, and you know a priori that the proportion is in the ballpark of 1/2. You could refine this to a more accurate estimate with Monte Carlo, throwing darts at the box and seeing how many land in the region of interest.
But in practice, the regions we want to estimate are small relative to any box we’d put around them. For example, suppose you want to estimate the volume of a unit ball in n dimensions by throwing darts at the unit cube in n dimensions. When n = 10, only about 1 dart in 400 will land in the ball. When n = 100, only one dart out of 1070 will land inside the ball. (See more here.) It’s very likely you’d never have a dart land inside the ball, no matter how much computing power you used.
If no darts land inside the region of interest, then you would estimate the volume of the region of interest to be zero. Is this a problem? Yes and no. The volume is very small, and the absolute error in estimating a small number to be zero is small. But the relative is 100%.
(For an analogous problem, see this discussion about the approximation sin(θ) = θ for small angles. It’s not just saying that one small number is approximately equal to another small number: all small numbers are approximately equal in absolute error! The small angle approximation has small relative error.)
If you want a small relative error in Monte Carlo integration, and you usually do, then you need to come up with a procedure that puts a larger proportion of integration points in the region of interest. One such technique is importance sampling, so called because it puts more samples in the important region. The closer the importance sampler fits the region of interest, the better the results will be. But you may not know enough a priori to create an efficient importance sampler.
So while the absolute accuracy of Monte Carlo integration does not depend on dimension, the problems you want to solve with Monte Carlo methods typically get harder with dimension.

![\frac{1}{\sqrt{2\pi}}\int_{-\infty}^\infty \left(\sum_{k=0}^N a_k\,H_k(x)\right) \exp(-x^2/2) \,dx = \sum_{k=0}^N a_k \, [k\, \mathrm{ even} ] \,k!!](https://www.johndcook.com/hermite_int.svg)