Yesterday I mentioned μRNG, a true random number generator (TRNG) that takes physical sources of randomness as input. These sources are independent but non-uniform. This post will present the entropy extractor μRNG uses to take non-uniform bits as input and produce uniform bits as output.
We will present Python code for playing with the entropy extractor. (μRNG is extremely efficient, but the Python code here is not; it’s just for illustration.) The code will show how to use the pyfinite library to do arithmetic over a finite field.
Entropy extractor
The μRNG generator starts with three bit streams—X, Y, and Z—each with at least 1/3 bit min-entropy per bit.
Min-entropy is Rényi entropy with α = ∞. For a Bernoulli random variable, that takes on two values, one with probability p and the other with probability 1 − p, the min-entropy is
−log2 max(p, 1 − p).
So requiring min-entropy of at least 1/3 means the two probabilities are less than 2−1/3 = 0.7937.
Take eight bits (one byte) at a time from X, Y, and Z, and interpret each byte as an element of the finite field with 28 elements. Then compute
X*Y + Z
in this field. The resulting stream of bits will be independent and uniformly distributed, or very nearly so.
Purified noise
Just a quick aside. Normally you want to remove noise from data to reveal a signal. Said another way, you want to split the data into signal and noise so you can throw out the noise. Here the goal is the opposite: we want to remove any unwanted signal in order to create pure noise!
Python implementation
We will need the bernoulli class for generating our input bit streams, and the pyfinite for doing finite field arithmetic on the bits.
from scipy.stats import bernoulli
from pyfinite import ffield
And we will need a couple bit manipulation functions.
def bits_to_num(a):
"Convert an array of bits to an integer."
x = 0
for i in range(len(a)):
x += a[i]*2**i
return x
def bitCount(n):
"Count how many bits are set to 1."
count = 0
while(n):
n &= n - 1
count += 1
return count
The following function generates random bytes using the entropy extractor. The input bit streams have p = 0.79, corresponding to min-entropy 0.34.
def generate_byte():
"Generate bytes using the entropy extractor."
b = bernoulli(0.79)
x = bits_to_num(b.rvs(8))
y = bits_to_num(b.rvs(8))
z = bits_to_num(b.rvs(8))
F = ffield.FField(8)
return F.Add(F.Multiply(x, y), z)
Note that 79% of the bits produced by the Bernoulli generator will be 1’s. But we can see that the output bytes are about half 1’s and half 0’s.
s = 0
N = 1000
for _ in range(N):
s += bitCount( generate_byte() )
print( s/(8*N) )
This returned 0.50375 the first time I ran it and 0.49925 the second time.
For more details see the μRNG paper.
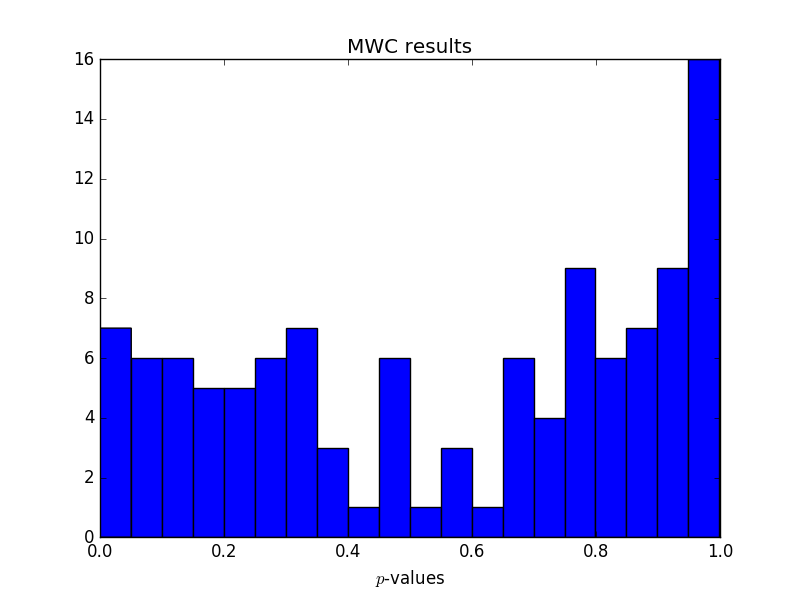
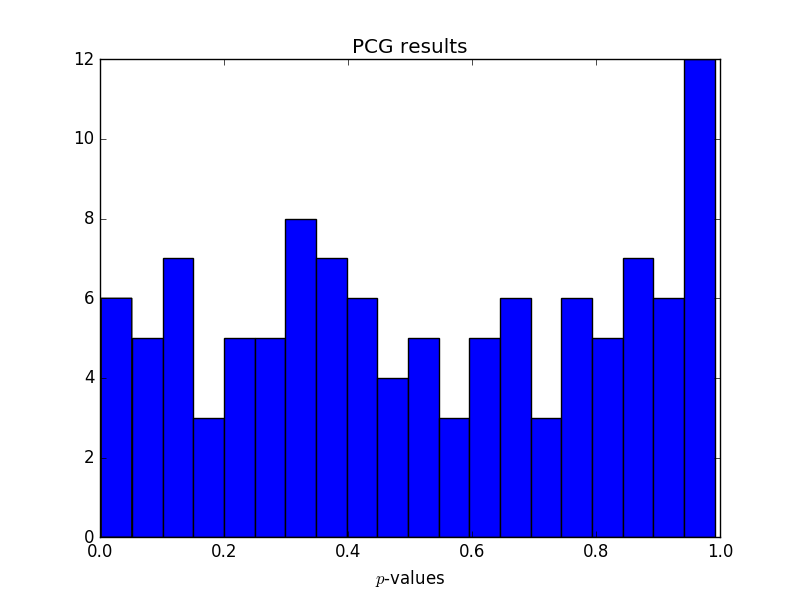
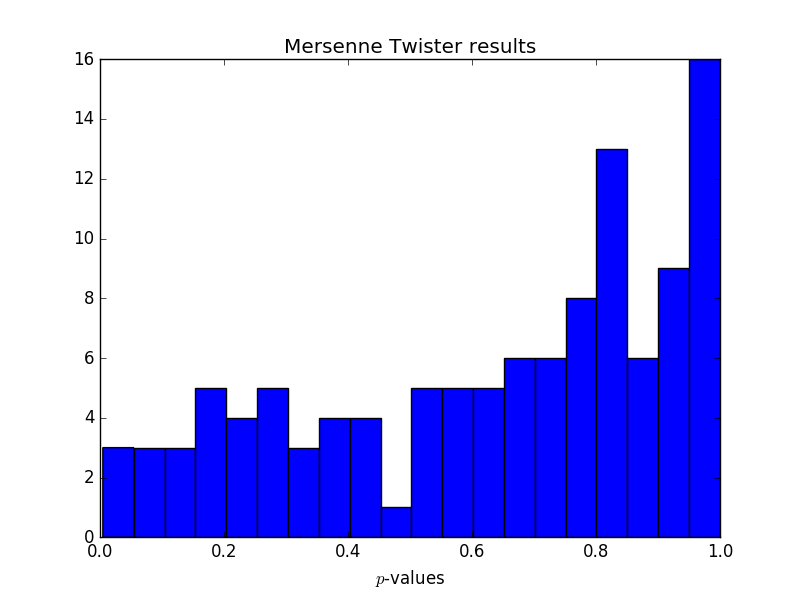
Update: RNG test suite results
I ran an experiment, creating streams of biased data and running them through the entropy extractor. The first post in the series, NIST STS, explains the set up. The last post in the series, using TestU01, summarizes the results. In a nutshell, the extractor passes STS and DIEHARDER, but fails PractRand and TestU01.