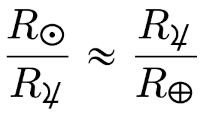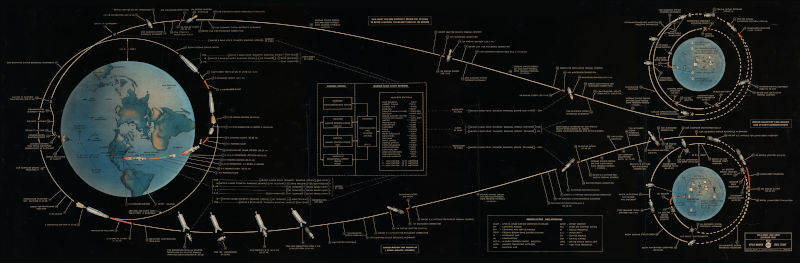
Suppose a spaceship is headed from the earth to the moon. At some point we say that the ship has left the earth’s sphere of influence is now in the moon’s sphere of influence (SOI). What does that mean exactly?
Wrong explanation #1
One way you’ll hear it described is that the moon’s sphere of influence is the point at which the earth is no longer pulling on the spaceship, but that’s nonsense. Everything has some pull on everything else, so how do you objectively say the earth’s pull is small enough that we’re now going to call it zero? And as we’ll see below, the earth’s pull is still significant even when the spaceship leaves earth’s SOI.
Wrong explanation #2
Another explanation you’ll hear is the moon’s sphere of influence is the point at which the moon is pulling on the spaceship harder than the earth is. That’s a better explanation, but still not right.
The distance from the earth to the moon is about 240,000 miles, and the radius of the moon’s SOI is about 40,000 miles. So when a spaceship first enters the moon’s SOI, it is five times closer to the moon than to the earth.
Newton’s law of gravity says gravitational force between two bodies is proportional to the product of their masses and inversely proportional to the square of the distance. The mass of the earth is about 80 times that of the moon. So at the moon’s SOI boundary, the pull of the earth is 80/25 times as great as that of the moon, about three times greater.
Correct exlanation
So what does sphere of influence mean? The details are a little complicated, but essentially the moon’s sphere of influence is the point at which it’s more accurate to say the ship is orbiting the moon than to say it is orbiting the earth.
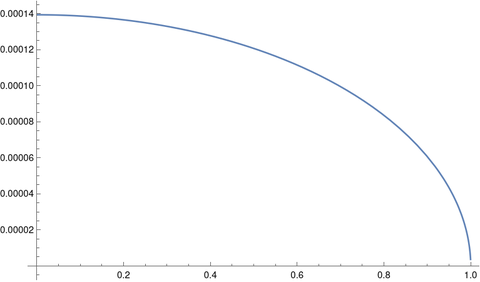
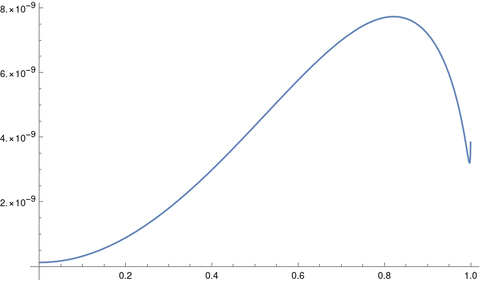
How can we say it’s better to think of the ship orbiting the moon than the earth when the earth is pulling on the ship three times as hard as the moon is? What matters is not so much the force of earth’s gravity as the effect of that force on the equations of motion.
The motion of an object between the earth and the moon could be viewed as an orbit around earth, with the moon exerting a perturbing influence, or as an orbit around the moon, with the earth exerting a perturbing influence.
At the boundary of the moon’s SOI the effect of the earth perturbing the ship’s orbit around the moon is equal to the effect of the moon perturbing its orbit around the earth. It’s a point at which it is convenient to switch perspectives. It’s not a physical boundary [1]. Also, the “sphere” of influence is not exactly a sphere but an approximately spherical region.
The moon has an effect on the ship’s motion when it’s on our side of the moon’s SOI, and the earth still has an effect on its motion after it has crossed into the moon’s SOI.
Calculating the SOI radius
As a rough approximation, the SOI boundary is where the ratio of the distances to the two bodies, e.g. moon and earth, equals the ratio of their masses to the exponent 2/5:
r/R = (m/M)2/5.
This approximation is better when the mass M is much larger than the mass m. For the earth and the moon, the equation is good enough for back-of-the-envelope equations but not accurate enough for planning a mission to the moon. Using the round numbers in this post, the left side of the equation is 1/5 = 0.2 and the right side is (1/80)0.4 = 0.17.
Context
Everything above has been in the context of the earth-moon system. Sphere of influence is defined relative to two bodies. When we spoke of a spaceship leaving the earth’s sphere of influence, we implicitly meant that it was leaving the earth’s sphere of influence relative to the moon.
Relative to the sun, the earth’s sphere of influence reaches roughly 600,000 miles. You could calculate this distance using the equation above. A spaceship like Artemis leaves the earth’s sphere of influence relative to the moon at some point, but never leaves the earth’s sphere of influence relative to the sun.
Related posts
[1] The sphere of influence sounds analogous to a continental divide, where rain falling on one side of the line ends up in one ocean and rain falling on the other side ends up in another ocean. But it’s not that way. I suppose you could devise an experiment to determine which side of the SOI you’re on, but it would not be a simple experiment. An object placed between the earth and the moon at the SOI boundary would fall to the earth unless it had sufficient momentum toward the moon.