The latest INFORMS podcast has an interview with David Alderson speaking about network science and protecting national infrastructure. He criticizes a couple network studies by saying the results are mathematically correct but the conclusions they draw are wrong because the models left out important details that would change the recommendations.
Month: May 2010
Sudden wealth
From Paul Buchheit’s blog post What to do with your millions:
Many people with jobs have a fantasy about all the amazing things they would do if they didn’t need to work. In reality, if they had the drive and commitment to actually do those things, they wouldn’t let a job get in the way. Unfortunately, if given a lot of money, they are much more likely to end up addicted to crack, or even worse, World of Warcraft. If you’ve been institutionalized your entire life (school, work, etc.), it can be very difficult to adjust to life on “the outside”.
Losing patience with wastes of time
Peter Bergman wrote an HBR blog post last week How (any Why) to Stop Multitasking. Bergman tried to stop multitasking for a week as an experiment. His post lists six benefits from his experiment including this observation:
I lost all patience for things I felt were not a good use of my time.
Multitasking can mask the pain of doing something that doesn’t need to be done.
Thanks to Neal Richter for pointing out this article.
Update: See this post on the study that Bergman quotes on how multitasking lowers your IQ more than smoking marijuana does. The study made a big splash even though it had a ridiculous design.
Related posts
A few questions with Frederick Brooks
The shelf life of software development books is typically two or three years, maybe five or ten years for a “classic.” Frederick Brooks, however, wrote a book on software development in 1975 that remains a best-seller: The Mythical Man-Month. His book has remained popular because he wrote about human nature as applied to software development, not the hottest APIs and development fads from the 1970s.
Frederick Brooks has written a new book that should also enjoy exceptional shelf life, The Design of Design: Essays from a Computer Scientist (ISBN 0201362988). In this book, Brooks looks back over a long successful career in computing and makes insightful observations about design.

The following interview comes from an email exchange with Frederick Brooks.
JC: You did a PhD in math with Howard Aiken in 1956. Did you study numerical analysis? Did you intend at the time to have a career in computing?
FB: Oh, yes indeed. That’s why I went to Aiken’s lab for graduate work.
JC: I was struck by your comments on conceptual integrity, particularly this quote: “Most great works have been made by one mind. The exceptions have been made by two minds.” Could you say more about that?
FB: I give lots of examples in the book of the one mind case, and a few of the two-mind case.
JC: You said in your book that your best management decision was sending E. J. Codd to get his PhD. That certainly paid off well. Could you share similar examples of successful long-term investments?
FB: Well, IBM’s decision to gamble everything on the System/360, terminating six successful product lines to do so, is a great example. DARPA’s funding of the development of the ARPAnet, ancestor to the Internet, is another great example.
JC: What are some technologies from decades ago that are being rediscovered?
FB: I find it useful to write first drafts of serious things, such as scientific papers and books, by hand with a felt-tip pen. I can type faster than I can think, so composing on a keyboard yields unnecessary wordiness. Writing by hand matches my thinking and writing speeds, and the result is leaner and cleaner.
JC: What are some that have not become popular again but that you think should be reconsidered?
FB: Probably the previous example answers this question better than it does the previous question.
JC: Apart from technological changes, how have you seen the workplace change over your career?
FB: I’ve been in academia for the past 46 years. The biggest change in academia is a consequence of personal computers and networks: faculty members don’t use secretaries as such, they write their own letters, and make their own phone calls. Our assistants are indeed administrative assistants, rather than secretaries.
JC: What change would you like to see happen as a result of people reading your new book?
FB: Even more recognition of the role of a chief designer, separate from a project manager, in making a new artifact, and more attention to choosing and growing such.
* * *
Update: Three years after this interview, I had a chance to meet Fred Brooks in person at the Heidelberg Laureate Forum.
Related links:
Other interviews:
Computing before Fortran
In the beginning was Fortran. Or maybe not.
It’s easy to imagine that no one wrote any large programs before there were compilers, but that’s not true. The SAGE system, for example, involved 500,000 lines of assembly code and is regarded as one of the most successful large computer systems ever developed. Work on SAGE began before the first Fortran compiler was delivered in 1957.
The Whirlwind computer that ran SAGE had a monitor, keyboard, printer, and modem. It also had a light gun, a precursor to the mouse. It’s surprising that all this came before Fortran.
Related posts
Being a dreamer is hard work
From Douglas Engelbart, inventor of the computer mouse:
I confess that I am a dreamer. Someone once called me just a dreamer. That offended me, the just part; being a real dreamer is hard work. It really gets hard when you start believing your dreams.
Army surplus flamethrowers
It’s hard to imagine the amount of equipment the US Army decommissioned after World War II: parachutes, diesel engines, Jeeps, etc. Apparently even flamethrowers were up for grabs.
An enterprising merchant in Quakertown, Pennsylvania ran a newspaper ad for military flamethrowers, pitching the weapon as a handy household gadget that “destroys weeds, tree stumps, splits rocks, disinfects, irrigates. 100 practical uses. $22 for 4 gal. tank, torch, hose.”
Source: Bright Boys: The Making of Information Technology, page 145.
In defense of reinventing wheels
Sometimes reinventing the wheel can be a good thing. Jeff Atwood wrote an article that ends with this conclusion:
So, no, you shouldn’t reinvent the wheel. Unless you plan on learning more about wheels, that is.
You have to be very selective about which wheels you’re going to reinvent. Trying to do everything yourself from scratch is the road to poverty. But in your area of specialization, reinventing a few wheels is a good idea.
Buy, don’t build?
Years ago I subscribed to the “buy, don’t build” philosophy of software development. Pay $100 for a CD rather than spend weeks writing your own buggy knock-off of a commercial product, etc. (This isn’t limited to commercial software. Substitute “download an open source product” for “pay $100 for a CD” and the principle is still the same. Call it “download, don’t build” if you like.) I still believe “buy, don’t build” is basically good advice, though I’d make more exceptions now than I would have then.
When you buy a dozen incompatible components that each solve part of your problem, you now have two new problems: managing the components and writing code to glue the components together.
Managing components includes sorting out licenses and keeping track of versions. Commercial components may require purchasing support. Using open source components may require monitoring blogs and list servers to keep track of bug fixes and upgrades.
Writing the glue code is a bigger problem. Mike Taylor calls this “the library lie.” This is the idea that your problem becomes trivial once you find a set of libraries that together do what you need to do. But integrating all these libraries may be more work than writing more of the code yourself.
Related posts
Pure functions have side-effects
Functional programming emphasizes “pure” functions, functions that have no side effects. When you call a pure function, all you need to know is the return value of the function. You can be confident that calling a function doesn’t leave any state changes that will effect future function calls.
But pure functions are only pure at a certain level of abstraction. Every function has some side effect: it uses memory, it takes CPU time, etc. Harald Armin Massa makes this point in his PyCon 2010 talk “The real harm of functional programming.” (His talk is about eight minutes into the February 21, 2010 afternoon lightning talks: video.)
Even pure functions in programming have side effects. They use memory. They use CPU. They take runtime. And if you look at those evil languages, they are quite fast at doing Fibonacci or something, but in bigger applications you get reports “Hmm, I have some runtime problems. I don’t know how to get it faster or what it going wrong.
Massa argues that the concept of an action without side effects is dangerous because it disassociates us from the real world. I disagree. I appreciate his warning that the “no side effect” abstraction may leak like any other abstraction. But pure functions are a useful abstraction.
You can’t avoid state, but you can partition the stateful and stateless parts of your code. 100% functional purity is impossible, but 85% functional purity may be very productive.
Related posts
Normal approximation to logistic distribution
The logistic distribution looks very much like a normal distribution. Here’s a plot of the density for a logistic distribution.
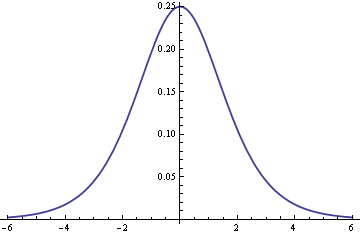
This suggests we could approximate a logistic distribution by a normal distribution. (Or the other way around: sometimes it would be handy to approximate a normal distribution by a logistic. Always invert.)
But which normal distribution approximates a logistic distribution? That is, how should we pick the variance of the normal distribution?
The logistic distribution is most easily described by its distribution function (CDF):
F(x) = exp(x) / (1 + exp(x)).
To find the density (PDF), just differentiate the expression above. You can add a location and scale parameter, but we’ll keep it simple and assume the location (mean) is 0 and the scale is 1. Since the logistic distribution is symmetric about 0, we set the mean of the normal to 0 so it is also symmetric about 0. But how should we pick the scale (standard deviation) σ for the normal?
The most natural thing to do, or at least the easiest thing to do, is to match moments: pick the variance of the normal so that both distributions have the same variance. This says we should use a normal with variance σ2 = π2/3 or σ = π/√3 . How well does that work? The following graph gives the answer. The logistic density is given by the solid blue line and the normal density is given by the dashed orange line.

Not bad, but we could do better. We could search for the value of σ that minimizes the difference between the two densities. The minimum occurs around σ = 1.6. Here is the revised graph using that value.

The maximum difference is almost three times smaller when we use σ = 1.6 rather than σ = π/√ 3 ≈ 1.8.
What if we want to minimize the difference between the distribution (CDF) functions rather than the density (PDF) functions? It turns out we end up at about the same spot: set σ to approximately 1.6. The two optimization problems don’t have exactly the same solution, but the two solutions are close.
The maximum difference between the distribution function of a logistic and the distribution of a normal with σ = 1.6 is about 0.017. If we used moment matching and set σ = π/√3, the maximum difference would be about 0.022. So moment matching does a better job of approximating the CDFs than approximating the PDFs. But we don’t need to decide between the two criteria since setting σ = 1.6 approximately minimizes both measures of the approximation.
Update: See an updated, more detailed article on this approximation here.