Someone left a comment this morning on my blog post on sinc and jinc integrals regarding the area of the lobes.
It would be nice to have the values of integrals of each lobe, i.e. integrals between 0 and multiples of pi. Anyone knows of such a table?
This post will include Python code to address that question. (Update: added asymptotic approximation. See below.)
First, let me back up and explain the context. The sinc function is defined as [1]
sinc(x) = sin(x) / x
and the jinc function is defined analogously as
jinc(x) = J1(x) / x,
substituting the Bessel function J1 for the sine function. You could think of Bessel functions as analogs of sines and cosines. Bessel functions often come up when vibrations are described in polar coordinates, just as sines and cosines come up when using rectangular coordinates.
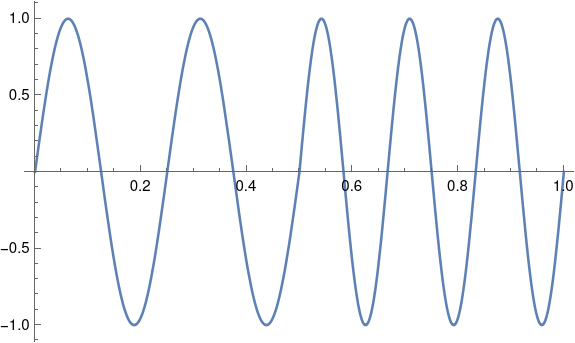
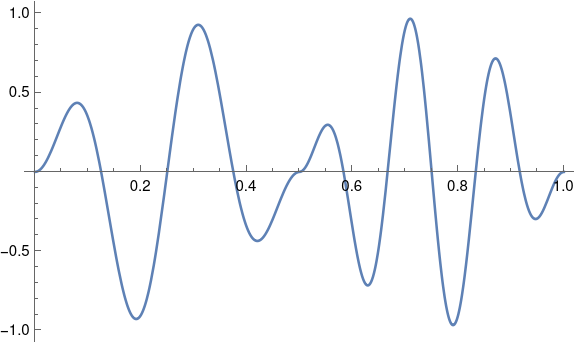
Here’s a plot of the sinc and jinc functions:

The lobes are the regions between crossings of the x-axis. For the sinc function, the lobe in the middle runs from −π to π, and for n > 0 the nth lobe runs from nπ to (n+1)π. The zeros of Bessel functions are not uniformly spaced like the zeros of the sine function, but they come up in application frequently and so it’s easy to find software to compute their locations.
First of all we’ll need some imports.
from scipy import sin, pi
from scipy.special import jn, jn_zeros
from scipy.integrate import quad
The sinc and jinc functions are continuous at zero, but the computer doesn’t know that [2]. To prevent division by zero, we return the limiting value of each function for very small arguments.
def sinc(x):
return 1 if abs(x) < 1e-8 else sin(x)/x
def jinc(x):
return 0.5 if abs(x) < 1e-8 else jn(1,x)/x
You can show via Taylor series that these functions are exact to the limits of floating point precision for |x| < 10−8.
Here’s code to compute the area of the sinc lobes.
def sinc_lobe_area(n):
n = abs(n)
integral, info = quad(sinc, n*pi, (n+1)*pi)
return 2*integral if n == 0 else integral
The corresponding code for the jinc function is a little more complicated because we need to compute the zeros for the Bessel function J1. Our solution is a little clunky because we have an upper bound N on the lobe number. Ideally we’d work out an asymptotic value for the lobe area and compute zeros up to the point where the asymptotic approximation became sufficiently accurate, and switch over to the asymptotic formula for sufficiently large n.
def jinc_lobe_area(n):
n = abs(n)
assert(n < N)
integral, info = quad(jinc, jzeros[n-1], jzeros[n])
return 2*integral if n == 0 else integral
Note that the 0th element of the array returned by jn_zeros is the first positive zero of J1; it doesn’t include the zero at the origin.
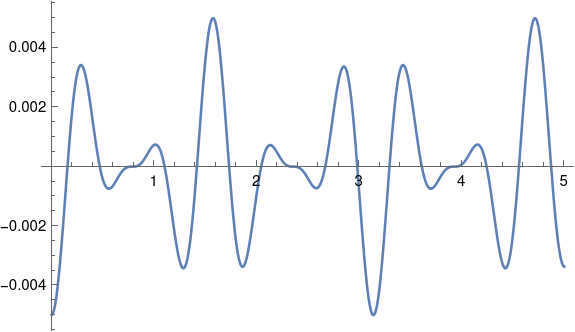
For both sinc and jinc, the even numbered lobes have positive area and the odd numbered lobes have negative area. Here’s a plot of the absolute values of the lobe areas.

Asymptotic results
We can approximate the area of the nth lobe of the sinc function by using a midpoint approximation for 1/x. It works out that the area is asymptotically equal to

We can do a similar calculation for the area of the nth jinc lobe, starting with the asymptotic approximation for jinc given here. We find that the area of the nth lobe of the jinc function is asymptotically equal to

To get an idea of the accuracy of the asymptotic approximations, here are the results for n=100.
sinc area: 0.00633455
asymptotic: 0.00633452
absolute error: 2.97e-8
relative error: 4.69e-6
jinc area: 0.000283391
asymptotic: 0.000283385
absolute error: 5.66e-9
relative error: 2.00e-5
More signal processing posts
[1] Some authors define sinc(x) as sin(πx)/πx. Both definitions are common.
[2] Scipy has a sinc function in scipy.special, defined as sin(πx)/πx, but it doesn’t have a jinc function.