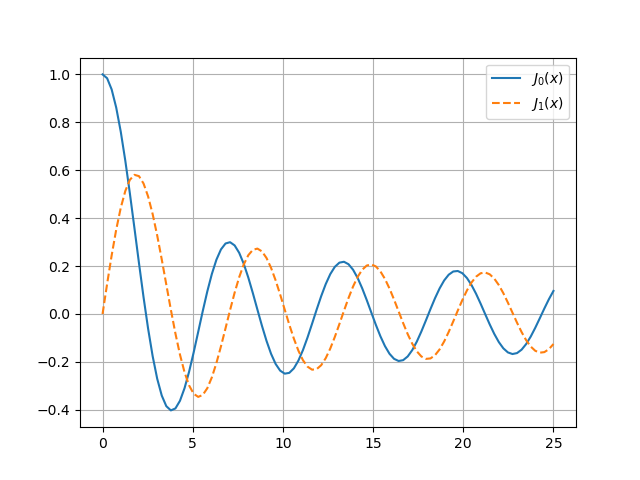
It’s occasionally necessary to evaluate a hypergeometric function at a large negative argument. I was working on a project today that involved evaluating F(a, b; c; z) where z is a large negative number.
The hypergeometric function F(a, b; c; z) is defined by a power series in z whose coefficients are functions of a, b, and c. However, this power series has radius of convergence 1. This means you can’t use the series to evaluate F(a, b; c; z) for z < −1.
It’s important to keep in mind the difference between a function and its power series representation. The former may exist where the latter does not. A simple example is the function f(z) = 1/(1 − z). The power series for this function has radius 1, but the function is defined everywhere except at z = 1.
Although the series defining F(a, b; c; z) is confined to the unit disk, the function itself is not. It can be extended analytically beyond the unit disk, usually with a branch cut along the real axis for z ≥ 1.
It’s good to know that our function can be evaluated for large negative x, but how do we evaluate it?
Linear transformation formulas
Hypergeometric functions satisfy a huge number of identities, the simplest of which are known as the linear transformation formulas even though they are not linear transformations of z. They involve bilinear transformations z, a.k.a. fractional linear transformations, a.k.a. Möbius transformations. [1]
One such transformation is the following, found in A&S 15.3.4 [2].
![]()
If z < 1, then 0 < z/(z − 1) < 1, which is inside the radius of convergence. However, as z goes off to −∞, z/(z − 1) approaches 1, and the convergence of the power series will be slow.
A more complicated, but more efficient, formula is A&S 15.3.7, a linear transformation formula relates F at z to two other hypergeometric functions evaluated at 1/z. Now when z is large, 1/z is small, and these series will converge quickly.

Related posts
[1] It turns out these transformations are linear, but not as functions of a complex argument. They’re linear as transformations on a projective space. More on that here.
[2] A&S refers to the venerable Handbook of Mathematical Functions by Abramowitz and Stegun.