Sometimes when people say they want random points, that’s not what they really want. Random points clump more than most people expect. Quasi-random sequences are not random in any mathematical sense, but they might match popular expectations of randomness better than the real thing, especially for aesthetic applications. If by “random” someone means “scattered around without a clear pattern and not clumped together” then quasi-random sequences might do the trick.
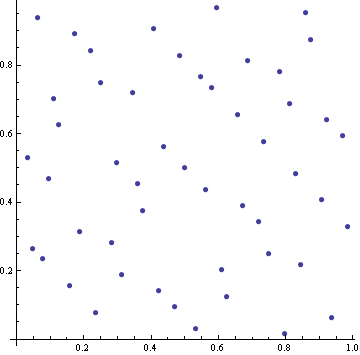
Here are the first 50 points in a quasi-random sequence of points in the unit square.
By contrast, here are 50 points in a unit square whose coordinates are uniform random samples.
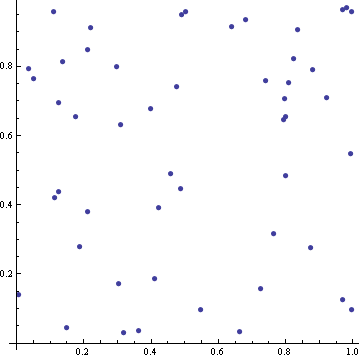
The truly random points clump together. Notice the cluster of three points in the top right corner. There are few other instances of pairs of points being very close together. Also, there are fairly large areas that don’t contain any random points. The quasi-random points by contrast are better spread out. They have a self-avoiding property that keeps them from clustering, and they fill the space more efficiently.
Quasi-random sequences could be confused with pseudo-random sequences. They’re not at all the same thing. Pseudo-random sequences are computer-generated sequences that in many ways behave as if they were truly random, even though they were produced by deterministic algorithms. For many practical purposes, including sensitive statistical tests, pseudo-random sequences are simply random sequences. (The “truly” random points above were technically “pseudo-random” points.)
The quasi-random points above were part of a Sobol sequence, a common quasi-random sequence. Other quasi-random sequences include the Halton sequence and the Hammersley sequence. Mathematically, these sequences are defined has having low-discrepancy. Roughly speaking, this means the “discrepancy” between the number of points that actually fall in a volume and the number of points you’d expect to fall in the same volume is small. See the Wikipedia article on quasi-random sequences for more mathematical details.
Besides being aesthetically useful, quasi-random sequences are useful in applied mathematics. Because these sequences explore a space more efficiently than random sequences, quasi-random sequences sometimes lead to more efficient high-dimensional integration algorithms than Monte Carlo integration. Quasi-Monte Carlo integration, i.e. integration based on quasi-random sequences rather than random sequences, is popular in financial applications. Art Owen has written insightful papers on Quasi-Monte Carlo integration (QMC). He has classified which integration problems can be efficiently computed via QMC methods and which cannot. In a nutshell, QMC works well when the effective dimension of a problem is significantly lower than the actual dimension. For example, a financial model might ostensibly depend on 1000 variables, but 50 of those variables contribute far more to the integrand than all the other variables. The integrand might essentially be a function of only 50 variables. In that case, QMC will work well. Note that it is not necessary to identify these 50 variables or do any change of variables. QMC just magically takes advantage of the situation.
One disadvantage of QMC integration is that it doesn’t naturally lead to an estimate of its own accuracy, unlike Monte Carlo integration. Several hybrid approaches have been proposed to combine QMC integration and Monte Carlo integration to get the efficiency of the former and the error estimates of the latter. For example, one could randomly jitter the quasi-random points or randomly permute their components. Some of these results are in Art Owen’s papers.
To read more about quasi-random sequences, see the book Random Number Generation and Quasi-Monte Carlo Methods.