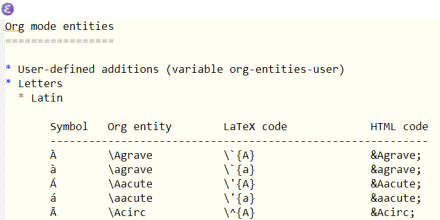
Suppose you type a little text into a text file, say “123”. If you open this file in a hex editor you’ll see
3132 33
because the ASCII value for the character ‘1’ is 0x31 in hex, ‘2’ corresponds to 0x32, and ‘3’ corresponds to 0x33. If your file is saved as utf-8 rather than ASCII, it makes absolutely no difference, as long as the file is UTF-8 encoded. By design, UTF-8 is backward compatible with the first 128 ASCII characters.
Next, let’s add some Greek letters. Now our file contains “123 αβγ”. The lower-case Greek alphabet starts at 0x03B1, so these three characters are 0x03B1, 0x03B2, and 0x03B3. Now let’s look at the file in our hex editor.
3132 3320 CEB1 CEB2 CEB3
The B1, B2, and B3 look familiar, but why do they have “CE” in front rather than “03”? This has to do with the details of UTF-8 encoding. If we looked at the same file with UTF-16 encoding, representing each character with 16 bits, the results look more familiar.
FEFF 0031 0032 0033 0020 03B1 03B2 03B3
So our ASCII characters—1, 2, 3, and space—are padded with a couple zeros, and we see the Unicode values of our Greek letters as we expect. But what’s the FEFF at the beginning? That’s a byte order mark (BOM) that my text editor inserted. This is an invisible marker saying that the bytes are stored in big-endian mode.
Going back to UTF-8, the ASCII characters are more compact, i.e. no zero padding, but why to the Greek letters start with “CE”?
3132 3320 CEB1 CEB2 CEB3
As I go into detail here, UTF-8 is a clever way to save space when representing mostly ASCII text. Since ASCII bytes start with 0, a byte starting with 1 signals that something special is happening and that the following bytes are to be interpreted differently.
In binary, 0xCE expands to
11001110
I’ll color-code the bits to make it easier to talk about them.
1 1 0 01110
The first 1 says that this byte does not simply represent a single character but is part of the encoding of a sequence of bytes encoding a character. The first 1 and the first 0, colored red, are bookends. The number of 1s in between, colored blue, says how many of the next bytes are part of this character. The bits after the first 0, colored black, are part of the character, and the rest follow in the next byte.
The continuation bytes begin with 10, and the remaining six bits are parts of a character. You know they’re not the start of a new character because there are no 1s between the first 1 and the first 0. With UTF-8, you can look at a byte in isolation and know whether it is an ASCII character, the beginning of a non-ASCII character, or the continuation of a non-ASCII character.
So now let’s look at 0xCEB1, with some spaces and colors added.
1 1 0 01110 10 110001
The black bits, 01110110001, are the bits of our character, and the binary number 1110110001 is 0x03B1 in hex. So we get the Unicode value for α. Similarly the rest of the bytes encode β and γ.
It’s was a coincidence that the last two hex characters of our Greek letters were recognizable in the hex dump of the UTF-8 encoding. We’ll always see the last hex character of the Unicode value in the hex dump, but not always the last two.
For another example, let’s look at a higher Unicode value, U+FB31. This is בּ, the Hebrew letter bet with a dot in the middle. This shows up in a hex editor as
EFAC B1
or in binary as
111011111010110010110001
Let’s break this up as before.
1 11 0 1111 10 101100 10 110001
The first bit is a 1, so we know we have some decoding to do. There are two 1s, colored blue, between the first 1 and the first 0, colored red. This says that the bits for our character, colored black, are stored in the remainder of the first byte and in the following two bytes.
So the bits of our character are
1111101100110001
which in hex is 0xFB31, the Unicode value of our character.