The trapezoid rule is a very simple method for estimating integrals. The idea is to approximate the area under a curve by a bunch of thin trapezoids and add up the areas of the trapezoids as suggested in the image below.
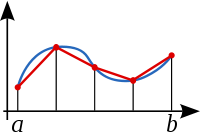
This is an old idea, probably older than the formal definition of an integral. In general it gives a crude estimation of the integral. If the width of the trapezoids is h, the error in using the trapezoid rule is roughly proportional to h2. It’s easier to do better. For example, Simpson’s rule is a minor variation on the trapezoid rule that has error proportional to h5.
So if the trapezoid rule is old and inaccurate, why does anyone care about it? Here are the surprises.
- You can still get a publication out of the trapezoid rule! In 1994, a doctor published a paper reinventing the trapezoid rule. Not only did the editors not recognize this ancient algorithm, the paper has been cited many times since it was published. (Update: more about the trapezoid paper here.)
- Although the trapezoid rule is inefficient in general, it can be shockingly efficient for periodic functions.
- The trapezoid rule can also be shockingly efficient for analytic functions that go to zero quickly, so called double exponential functions.
The last two observations are more widely applicable than you might think at first. What if you want to integrate something that isn’t periodic and isn’t a double exponential function? You may be able to do a change of variables that makes your integrand have one of these special forms. The article Fast Numerical Integration explains an integration method based on double exponential functions and includes C++ source code.
The potential efficiency of the trapezoid rule illustrates a general principle: a crude method cleverly applied can beat a clever technique crudely applied. The simplest numerical integration technique, one commonly taught in freshman calculus, can be extraordinarily efficient when applied with skill to the right problem. Conversely, a more sophisticated integration technique such as Gauss quadrature can fail miserably when naively applied.

![\begin{eqnarray*} P(X \geq Y) &=& \int \!\int _{[x > y]} f_X(x) f_Y(y) \, dy \, dx \\ &=& \int_{-\infty}^\infty \! \int_{-\infty}^x f_X(x) f_Y(y) \, dy \, dx \\ &=& \int_{-\infty}^\infty f_X(x) F_Y(x) \, dx end{eqnarray*}](http://www.johndcook.com/ineq_integral.svg)