Math and physics use Greek letters constantly, but seldom do they use letters from any other alphabet.
The only Cyrillic letter I recall seeing in math is sha (Ш, U+0428) for the so-called Dirac comb distribution.
One Hebrew letter is commonly used in math, and that’s aleph (א, U+05D0). Aleph is used fairly often, but other Hebrew letters are much rarer. If you see any other Hebrew letter in math, it’s very likely to be one of the next three letters: beth (ב, U+05D1), gimel (ג, U+05D2), or dalet (ד, U+05D3).
To back up this claim, basic LaTeX only has a command for aleph (unsurprisingly, it’s \aleph). AMS-LaTeX adds the commands \beth, \gimel, and \daleth, but no more. Those are the only Hebrew letters you can use in LaTeX without importing a package or using XeTeX so you can use Unicode symbols.
Not only are Hebrew letters rare in math, the only area of math that uses them at all is set theory, where they are used to represent transfinite numbers.
So in short, if you see a Hebrew letter in math, it’s overwhelmingly likely to be in set theory, and it’s very likely to be aleph, or possibly beth, gimel, or dalet.
But today I was browsing through Morse and Feschbach and was very surprised to see the following on page 324.
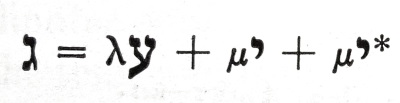
I’ve never seen a Hebrew letter in applied math, and I’ve never seen ayin (ע, U+05E2) or yod (י, U+05D9) used anywhere in math.
In context, the authors had used Roman letters, Fraktur letters, and Greek letters and so they’d run out of alphabets. The entity denoted by gimel is related to a tensor the authors denoted with g, so presumably they used the Hebrew letter that sounds like “g”. But I have no idea why they chose ayin or yod.