Suppose we have a differential equation of the form
x” + b(t) x‘ + c(t) x = f(t)
where the functions b and c are periodic with the same period T.
When does the equation above have a solution with period T?
Suppose we have a differential equation of the form
x” + b(t) x‘ + c(t) x = f(t)
where the functions b and c are periodic with the same period T.
When does the equation above have a solution with period T?
Let p be a prime number. This post explores a relationship between the number of digits in the reciprocal of p and in the reciprocal of powers of p.
By the number of digits in a fraction we mean the period of the decimal representation as a repeating sequence. So, for example, we say there are 6 digits in 1/7 because
1/7 = 0.142857 142857 …
We will assume our prime p is not 2 or 5 so that 1/p is a repeating decimal.
If 1/p has r digits, is there a way to say how many digits 1/pa has? Indeed there is, and usually the answer is
r pa-1.
So, for example, we would expect 1/7² to have 6×7 digits, and 1/7³ to have 6×7² digits, which is the case.
As another example, consider
1/11 = 0.09 09 09 …
Since 1/11 has 2 digits, we’d expect 1/121 to have 22 digits, and it does.
You may be worried about the word “usually” above. When does the theorem not hold? For primes p less than 1000, the only exceptions are p = 3 and p = 487. In general, how do you know whether a given prime satisfies the theorem? I don’t know. I just ran across this, and my source [1] doesn’t cite any references. I haven’t thought about it much, but I suspect you could get to a proof starting from the theorem given here.
What if we’re not working in base 10? We’ll do a quick example in duodecimal using bc.
$ bc -lq
obase=12
1/5
.2497249724972497249
Here we fire up the Unix calculator bc and tell it to set the output base to 12. In base 12, the representation of 1/5 repeats after 4 figures: 0.2497 2497 ….
We expect 1/5² to repeat after 4×5 = 20 places, so let’s set the scale to 40 and see if that’s the case.
scale = 40
1/25
.05915343A0B62A68781B05915343A0B62A6878
OK, it looks like it repeats, but we didn’t get 40 figures, only 38. Let’s try setting the scale larger so we can make sure the full cycle of figures repeats.
scale=44
1/25
.05915343A0B62A68781B05915343A0B62A68781B0
That gives us 40 figures, and indeed the first 20 repeat in the second 20. But why did we have to set the scale to 44 to get 40 figures?
Because the scale sets the precision in base 10. Setting the scale to 40 does give us 40 decimal places, but fewer duodecimal figures. If we solve the equation
10x = 1240
we get x = 43.16… and so we round x up to 44. That tells us 44 decimal places will give us 40 duodecimal places.
[1] Recreations in the Theory of Numbers by Alfred H. Beiler.
There are two techniques in software development that have an almost gnostic mystique about them: monads and macros.
As with everything people do, monads and macros are used with mixed motives, for pride and for pragmatism.
As for pride, monads and macros have just the right barrier to entry: high enough to keep out most programmers, but not so high as to be unsurmountable with a reasonable amount of effort. They’re challenging to learn, but not so challenging that you can’t show off what you’ve learned to a wide audience.
As for pragmatism, both monads and macros can be powerful in the right setting. They’re both a form of information hiding.
Monads let you concentrate on functions by providing a sort of side channel for information associated with those functions. For example, you may have a drawing program and want to compose a rotation and stretching. These may be ostensibly pure functions, but they also effect a log of operations that lets you undo actions. It would be burdensome to consider this log as an explicit argument passed into and returned from every operation. so you might keep this log information in a monad.
Macros let you hide the fact that your programming language doesn’t have features that you would like. Operator overloading is an example of adding the appearance of a new feature to a programming language. Macros take this much further, for better or for worse. If you think operator overloading is good because of its potential to clarify code, you’ll like macros. If you think operator overload is bad because of its potential for misuse, you definitely won’t like macros.
Few people are excited about both monads and macros; only one person that I know comes to mind.
Monads and macros appeal to opposite urges: the urge to impose rules and the urge to get around rules. There is a time for both, a time to build structure and a time to tear structure down.
Monads are most popular in Haskell, and macros in Lisp. These are very different languages and their communities have very different values [1].
The ideal Haskell program has such rigid structure that only correct code will compile. The ideal Lisp program is so flexible that it is essentially a custom programming language.
A Haskell programmer would like to say that a program is easy to reason about because of its mathematical structure. A Lisp programmer would like to say a program is easy to read because it maps well onto the problem at hand.
Lisp enthusiast Doug Hoyte says in his book Let Over Lambda
As we now know, nobody truly understands macros.
A Haskell programmer would find this horrifying, but a Lisp programmer would consider it an acceptable price to pay or even something fun to explore.
[1] Here I’m referring to archetypes, generalizations but not exaggerations. Of course no language community is monolithic, and an individual programmer will have different approaches to different tasks. But as a sweeping generalization, Haskell programmers value structure and Lisp programmers value flexibility.
I seem to run into Catalan numbers fairly regularly. This evening I ran into Catalan numbers while reading Stephen Wolfram’s book Combinators: A Centennial View [1]. Here’s the passage.
The number of combinator expressions of size n grows like
{2, 4, 16, 80, 448, 2688, 16896, 109824, 732160, 4978688}
or in general
2n CatalanNumber[n-1] = 2n Binomial[2n – 2, n – 1]/n
or asymptotically:
Specifically, Wolfram is speaking about S and K combinators. (See a brief etymology of combinator names here.)
The Catalan numbers are defined by
![]()
Replacing n with n-1 above shows that
CatalanNumber[n-1] = Binomial[2n – 2, n – 1]/n
as claimed above.
The formula for the number of combinators is easy to derive [1]. There are 2n ways to write down a string of n characters that are either S or K. Then the number of ways to add parentheses is the (n-1)st Catalan number, as explained here.
Wolfram’s asymptotic expression is closely related to a blog post I wrote two weeks ago called kn choose n. That post looked at asymptotic formulas for
![]()
and Catalan numbers correspond to f(n, 2)/(n + 1). That post showed that
![]()
The asymptotic estimate stated in Wolfram’s book follows by replacing n with n-1 above and multiplying by 2n/n. (Asymptotically there’s no difference between n and n-1 in the denominator.)
[1] Believe it or not, I’m reading this in connection with a consulting project. When Wolfram’s book first came out, my reaction was something like “Interesting, though it’ll never be relevant to me.” Famous last words.
[2] Later in the book Wolfram considers combinators made only using S. This is even simpler since are no choices of symbols; the only choice is where to put the parentheses, and CatalanNumber[n-1] tells you how many ways that can be done.
Suppose you’re asked to write a function that takes a number and returns a planet. We’ll number the planets in order from the sun, starting at 1, and for our purposes Pluto is the 9th planet.
Here’s an obvious solution:
def planet(n):
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
"Pluto"
]
# subtract 1 to correct for unit offset
return planets[n-1]
Now let’s have some fun with this and play a little code golf. Here’s a much shorter program.
def planet(n): return chr(0x263e+n)
I was deliberately ambiguous at the top of the post, saying the code should return a planet. The first function naturally interprets that to mean the name of a planet, but the second function takes it to mean the symbol of a planet.
The symbol for Mercury has Unicode value U+263F, and Unicode lists the symbols for the planets in order from the sun. So the Unicode character for the nth planet is the character for Mercury plus n. That would be true if we numbered the planets starting from 0, but conventionally we call Mercury the 1st planet, not the 0th planet, so we have to subtract one. That’s why the code contains 0x263e rather than 0x263f.
We could make the function just a tiny bit shorter by using a lambda expression and using a decimal number for 0x263e.
planet = lambda n: chr(9790+n)
Here’s a brief way to list the symbols from the Python REPL.
>>> [chr(0x263f+n) for n in range(9)]
['☿', '♀', '♁', '♂', '♃', '♄', '♅', '♆', '♇']
You may see the symbols for Venus and Mars above rendered with a colored background, depending on your browser and OS.
Here’s what the lines above looked like at my command line.
![]()
Here’s what the symbols looked like when I posted them on Twitter.
![]()
For reasons explained here, some software interprets some characters as emoji rather than literal characters. The symbols for Venus and Mars are used as emoji for female and male respectively, based on the use of the symbols in biology. Incidentally, these symbols were used to represent planets long before biologists used them to represent sexes.
Suppose X is a beta(a, b) random variable and Y is a beta(c, d) random variable. Define the function
g(a, b, c, d) = Prob(X > Y).
At one point I spent a lot of time developing accurate and efficient ways to compute g under various circumstances. I did this because when I worked at MD Anderson Cancer Center we spent thousands of CPU-hours computing this function inside clinical trial simulations.
For this post I want to outline how to compute g in a minimal environment, i.e. a programming language with no math libraries, when the parameters a, b, c, and d are all integers. The emphasis is on portability, not efficiency. (If we had access to math libraries, we could solve the problem for general parameters using numerical integration.)
In this technical report I develop several symmetries and recurrence relationships for the function g. The symmetries can be summarized as
g(a, b, c, d) = g(d, c, b, a) = g(d, b, c, a) = 1 − g(c, d, a, b).
Without loss of generality we assume a is the smallest argument. If not, apply the symmetries above to make the first argument the smallest.
We will develop a recursive algorithm for computing the function g by recurring on a. The algorithm will terminate when a = 1, and so we want a to be the smallest parameter.
In the technical report cited above, I develop the recurrence relation
g(a + 1, b, c, d) = g(a, b, c, d) + h(a, b, c, d)/a
where
h(a, b, c, d) = B(a + c, b + d) / B(a, b) B(c, d)
and B(x, y) is the beta function.
The equation above explains how to compute g(a + 1, b, c, d) after you’ve already computed g(a, b, c, d), which is what I often needed to do in applications. But we want to do the opposite to create a recursive algorithm:
g(a, b, c, d) = g(a – 1, b, c, d) + h(a – 1, b, c, d)/(a – 1)
for a > 1.
For the base case, when a = 1, we have
g(1, b, c, d) = B(c, b + d) / B(c, d).
All that’s left to develop our code is to evaluate the Beta function.
Now
B(x, y) = Γ(x + y) / Γ(x) Γ(y)
and
Γ(x) = (x – 1)!.
So all we need is a way to compute the factorial, and that’s such a common task that it has become a cliché.
The symmetries and recurrence relation above hold for non-integer parameters, but you need a math library to compute the gamma function if the parameters are not integers. If you do have a math library, the algorithm here won’t be the most efficient one unless you need to evaluate g for a sequence of parameters that differ by small integers.
***
For more on random inequalities, here’s the first of a nine-part sequence of blog posts.
There are similarities across Unix tools that I’ve seldom seen explicitly pointed out. For example, the dollar sign $ refers to the end of things in multiple contexts. In regular expressions, it marks the end of a string. In sed, it refers to last line of a file. In vi it is the command to move to the end of a line.
Think of various Unix utilities lined up in columns: a column for grep, a column for less, a column for awk, etc. I’m thinking about patterns that cut horizontally across the tools.
Tools are usually presented vertically, one tool at a time, and for obvious reasons. If you need to use grep, for example, then you want to learn grep, not study a dozen tools simultaneously, accumulating horizontal cross sections like plastic laid down by a 3D printer, until you finally know what you need to get your job done.
On the other hand, I think it would be useful to point out some of the similarities across tools that experienced users pick up eventually but seldom verbalize. At a minimum, this would make an interesting blog post. (That’s not what this post is; I’m just throwing out an idea.) There could be enough material to make a book or a course.
I used the word etymology in the title, but that’s not exactly what I mean. Maybe I should have said commonality. I’m more interested in pedagogy than history. There are books on Unix history, but that’s not quite what I have in mind. I have in mind a reader who would appreciate help mentally organizing a big pile of syntax, not someone who is necessarily a history buff.
If the actual etymology isn’t too complicated, then history and pedagogy can coincide. For example, it’s helpful to know that sed and vi have common syntax that they inherited from ed. But pseudo-history, a sort of historical fiction, might be more useful than factually correct history with all its rabbit trails and dead ends. This would be a narrative that tells a story of how things could have developed, even while acknowledging that the actual course of events was more complicated.
Related post: Command option patterns
A few days ago I wrote a brief post showing an interesting pattern that comes from plotting sin(1), sin(2), sin(3), etc.
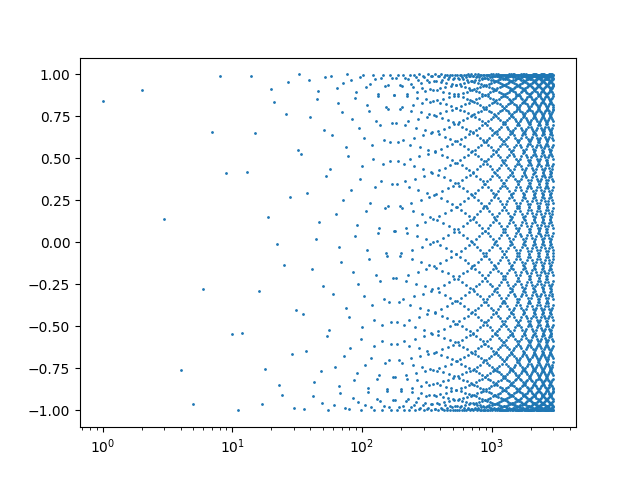
That post uses a logarithmic scale on the horizontal axis. You get a different, but also interesting, pattern when you use a linear scale.
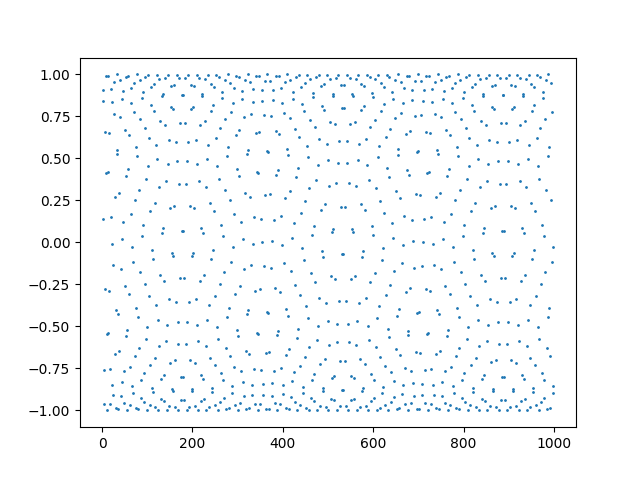
Someone commented that this looks like a projection of a carbon nanotube, and I think they’re right.
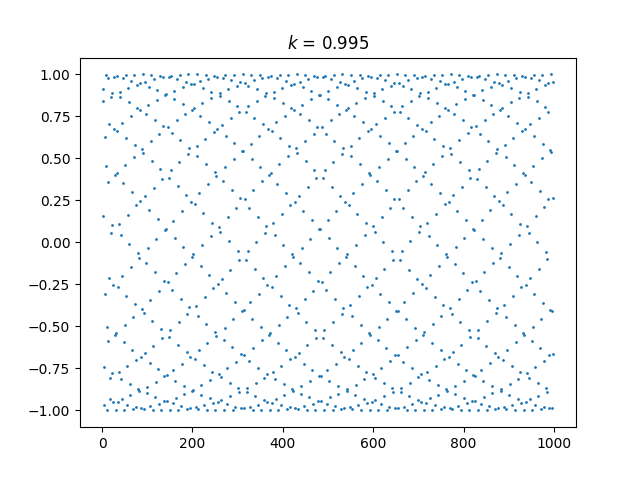
Let’s generalize this by plotting sin(kn) for integer n. The plot above corresponds to k = 1. Tiny changes to k make a big difference in the appearance of the plot.
Here’s k = 0.995:
And here’s k = 1.005:
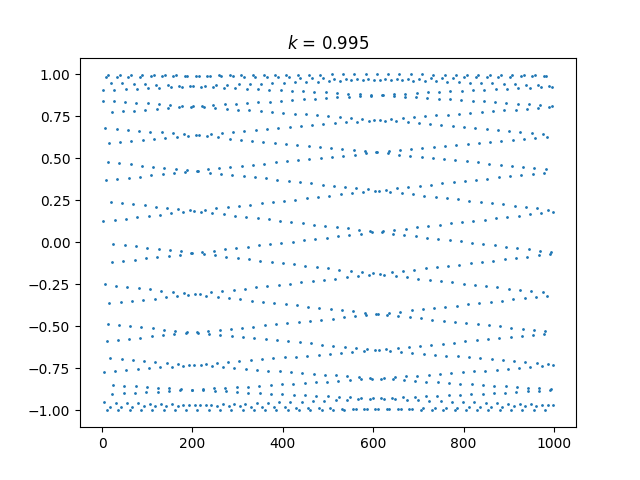
And here’s an animated plot, continuously changing k from 0.99 to 1.01.
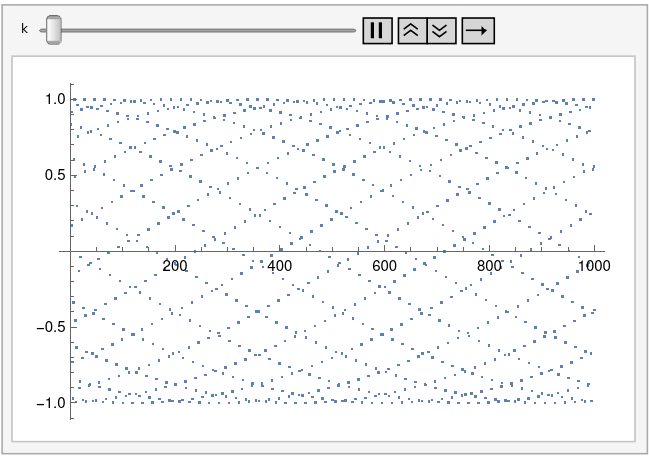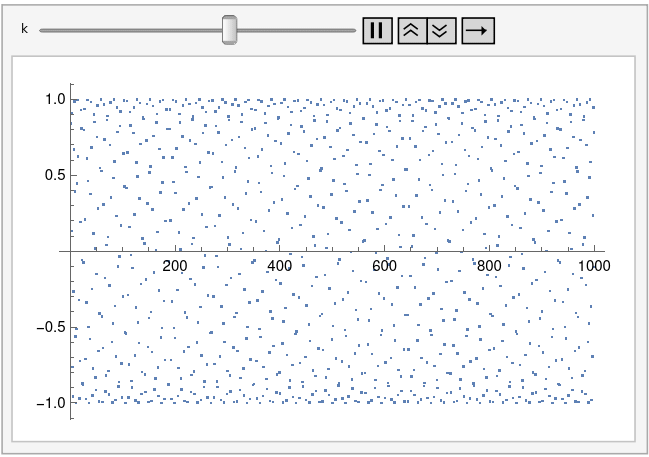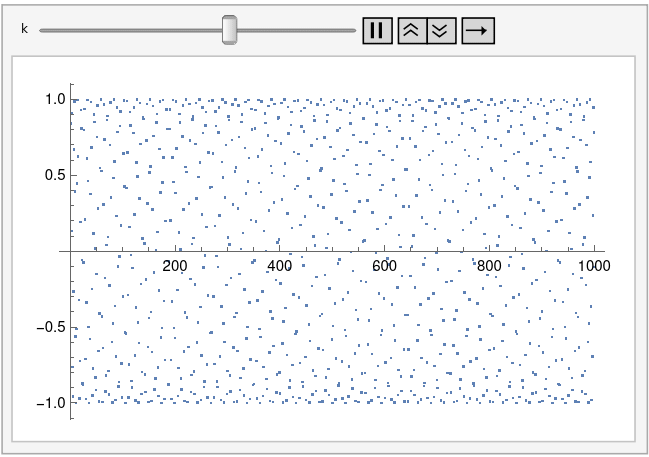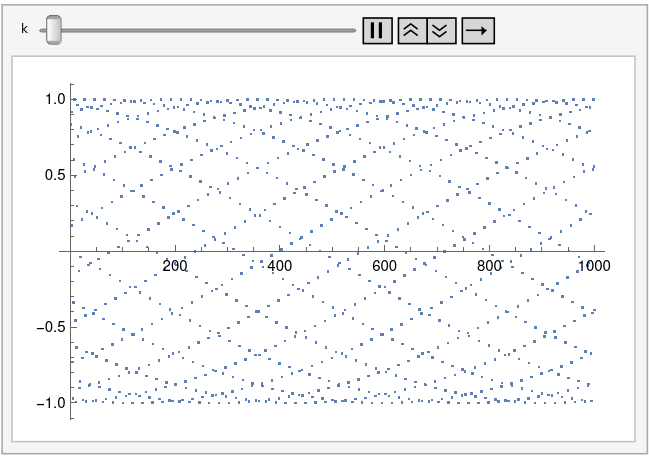
This animation was created using the following Mathematica code.
Animate[ListPlot[Table[Sin[k n], {n, 1, 1000}]], {k, 0.99, 1.01},
AnimationRate -> 0.001, TrackedSymbols :> {k}]
This post is about the word problem. When mathematicians talk about “the word problem” we’re not talking about elementary math problems expressed in prose, such as “If Johnny has three apples, ….”
The word problem in algebra is to decide whether two strings of symbols are equivalent given a set of algebraic rules. I go into a longer description here.
I know that the word problem is hard, but I hadn’t given much thought to why it is hard. It has always seemed more like a warning sign than a topic to look into.
“Why don’t we just …?”
“That won’t work because … is equivalent to the word problem.”
In logic terminology, the word problem is undecidable. There can be no algorithm to solve the word problem in general, though there are algorithms for special cases.
So why is the word problem undecidable? As with most (all?) things that have been shown to be undecidable, the word problem is undecidable because the halting problem is undecidable. If there were an algorithm that could solve the word problem in general, you could use it to solve the halting problem. The halting problem is to write a program that can determine whether another arbitrary program will always terminate, and it can be shown that no such program can exist.
The impulse for writing this post came from stumbling across Keith Conrad’s expository article Why word problems are hard. His article goes into some of the algebraic background of the problem—free groups, (in)finitely generated groups, etc.—and gives some flavor for why the word problem is harder than it looks. The bottom line is that the word problem is hard because the halting problem is hard, but Conrad’s article gives you a little more of an idea what’s going on that just citing a logic theorem.
I still don’t have a cocktail-party answer for why the word problem is hard. Suppose a bright high school student who had heard of the word problem were at a cocktail party (drinking a Coke, of course) and asked why the word problem is hard. Suppose also that this student had not heard of the halting problem. Would the simplest explanation be to start by explaining the halting problem?
Suppose we change the setting a bit. You’re teaching a group theory course and the students know about groups and generators, but not about the halting problem, how might you give them a feel for why the word problem is hard? You might ask them to read Keith Conrad’s paper and point out that it shows that simpler problems than the word problem are harder than they seem at first.
The symbols ≪ and ≫ may be confusing the first time you see them, but they’re very handy.
The symbol ≪ means “much less than, and its counterpart ≫ means “much greater than”. Here’s a little table showing how to produce the symbols.
|-------------------+---------+-------+------|
| | Unicode | LaTeX | HTML |
|-------------------+---------+-------+------|
| Much less than | U+226A | \ll | ≪ |
| Much greater than | U+226B | \gg | ≫ |
|-------------------+---------+-------+------|
Of course “much” depends on context. Is 5 much less than 7? It is if you’re describing the height of people in feet, but maybe not in the context of prices of hamburgers in dollars.
Sometimes you’ll see ≫, or more likely >> (two greater than symbols), as slang for “is much better than.” For example, someone might say “prototype >> powerpoint” to convey that a working prototype is much better than a PowerPoint pitch deck.
The symbols ≪ and ≫ can make people uncomfortable because they’re insider jargon. You have to know the context to understand how to interpret them, but they’re very handy if you are an insider. All jargon is like this.
Below are some examples of ≪ and ≫ in practice.
You might see somewhere that for |b| ≪ a, the following approximation holds:
![]()
So when is |b| much less than a? That’s up to you. If, in your context, you decide that b/a is small, the approximation error will be an order of magnitude smaller.
Suppose you need to know √103 to a couple decimal places. Here a = 100 and b = 3. The ratio b/a = 0.03, and your error should be small relative to 0.03, so the approximation above should be good enough. Let’s see if that’s right.
The approximation above gives
√103 ≈ √100 + 3/2√100 = 10 + 3/20 = 10.15
and the exact value of √103 is 10.14889…, and so we did get two correct decimal places, and we nearly got three.
Rather than saying a variable is “small,” we might say it is much less than 1. For example, you may see
sin θ ≈ θ
for |θ| ≪ 1. If θ is small, the error in the approximation above is very small.
A few years I wrote a 700-word blog post unpacking in detail what the previous sentence means. A lot of people memorize “You can replace sin θ with θ for small angles” without thoroughly understanding what this means. How small is small enough? The post explains how to know.
Sometimes you see something like n ≫ 1 to indicate that n must be large. For example, Stirling’s formula for factorials says
![]()
for n ≫ 1. For instance, if n = 10, the approximation above has an error of less than 1%.
Note that the approximation error above is small relative to the exact value. The relative error is small, not the absolute error. The error in the example is more than 30,000, but this value is small relative to 10! = 3,628,800.
It’s often harder to tell from context when something is large than when it is small.
If an approximation holds for |x| ≪ 1, there’s often an implicit power series in the background, and the error is on the order of x². That’s the case in our square root approximation above. The sine approximation is even better, with error on the order of x³.
But if an approximation holds for x ≫ 1, there’s often an implicit asymptotic series in the background, and these are more subtle. You likely need more context to how large x needs to be for a particular application.