A common technique for numerically evaluating functions is to use a power series for small arguments and an asymptotic series for large arguments. This might be refined by using a third approach, such as rational approximation, in the middle.
The error function erf(x) has alternating series on both ends: its power series and asymptotic series both are alternating series, and so both are examples that go along with the previous post.
The error function is also a hypergeometric function, so it’s also an example of other things I’ve written about recently, though with a small twist.
The error function is a minor variation on the normal distribution CDF Φ. Analysts prefer to work with erf(x) while statisticians prefer to work with Φ(x). See these notes for translating between the two.
Power series
The power series for the error function is
![]()
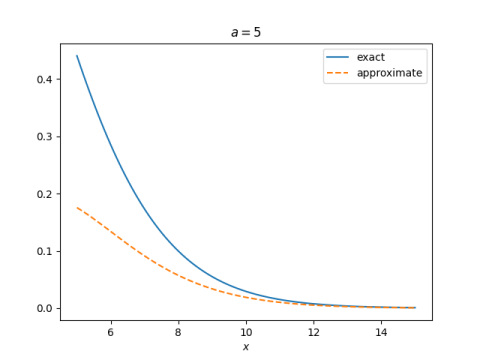
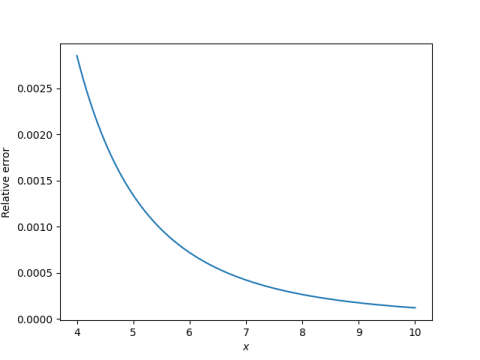
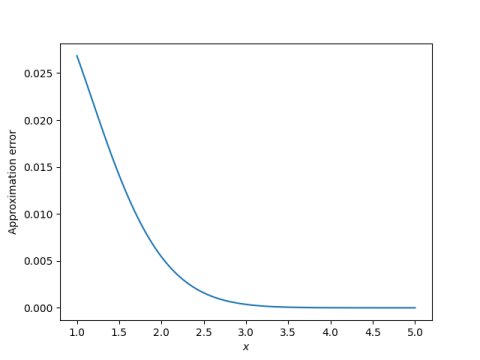
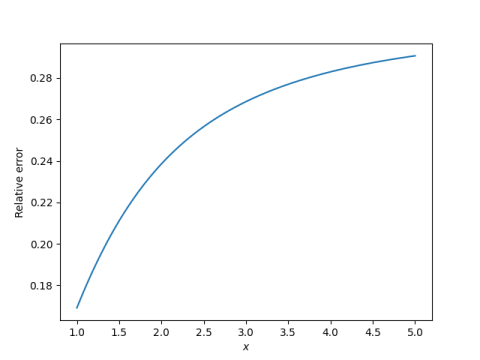
The series converges for all x, but it is impractical for large x. For every x the alternating series theorem eventually applies, but for large x you may have to go far out in the series before this happens.
Asymptotic series
The complementary error function erfc(x) is given by
erfc(x) = 1 − erf(x).
Even though the relation between the two functions is trivial, it’s theoretically and numerically useful to have names for both functions. See this post on math functions that don’t seem necessary for more explanation.
The function erfc(x) has an alternating asymptotic series.

Here a!!, a double factorial, is the product of the positive integers less than or equal to a and of the same parity as a. Since in our case a = 2n − 1, a is odd and so we have the product of the positive odd integers up to and including 2n − 1. The first term in the series involves (−1)!! which is defined to be 1: there are no positive integers less than or equal to −1, so the double factorial of −1 is an empty product, and empty products are defined to be 1.
Confluent hypergeometric series
The error function is a hypergeometric function, but of a special kind. (As is often the case, it’s not literally a hypergeometric function but trivially related to a hypergeometric function.)
The term “hypergeometric function” is overloaded to mean two different things. The strictest use of the term is for functions F(a, b; c; x) where the parameters a and b specify terms in the numerator of coefficients and the parameter c specifies terms in the denominator. You can find full details here.
The more general use of the term hypergeometric function refers to functions that can have any number of numerator and denominator terms. Again, full details are here.
The special case of one numerator parameter and one denominator parameter is known as a confluent hypergeometric function. Why “confluent”? The name comes from the use of these functions in solving differential equations. Confluent hypergeometric functions correspond to a case in which two singularities of a differential equation merge, like the confluence of two rivers. More on hypergeometric functions and differential equations here.
Without further ado, here are two ways to relate the error function to confluent hypergeometric functions.
![]()
The middle expression is the same as power series above. The third expression is new.