Suppose you take factorials of a lot of numbers and look at the leading digit of each result. You could argue that there’s no apparent reason that any digit would be more common than any other, so you’d expect each of the digits 1 through 9 would come up 1/9 of the time. Sounds plausible, but it’s wrong.
The leading digits of factorials follow Benford’s law as described in the previous post. In fact, factorials follow Benford’s law even better than physical constants do. Here’s a graph of the leading digits of the factorials of 1 through 500.
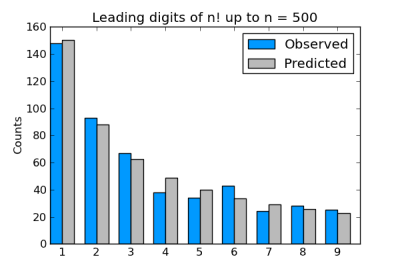
In the remainder of this post, I’ll explain why Benford’s law should apply to factorials, make an aside on statistics, and point out an interesting feature of the Python code used to generate the chart above.
Why Benford’s law applies
Here’s a hand-waving explanation. One way to justify Benford’s law is to say that physical constants are uniformly distributed, but on a logarithmic scale. The same is true for factorials, and it’s easier to see why.
The leading digits of the logarithms depend on their logarithms in base 10. The gamma function extends the factorial function and it is log-convex. The logarithm of the gamma function is fairly flat (see plot here), and so the leading digits of the log-gamma function applied to integers are uniformly distributed on a logarithmic scale. (I’ve mixed logs base 10 and natural logs here, but that doesn’t matter. All logarithms are the same up to a multiplicative constant. So if a plot is nearly linear on a log10 scale, it’s nearly linear on a natural log scale.)
Update: Graham gives a link in the comments below to a paper proving that factorials satisfy Benford’s law exactly in the limit.
Uniform on what scale?
This example brings up an important principle in statistics. Some say that if you don’t have a reason to assume anything else, use a uniform distribution. For example, some say that a uniform prior is the ideal uninformative prior for Bayesian statistics. But you have to ask “Uniform on what scale?” It turns out that the leading digits of physical constants and factorials are indeed uniformly distributed, but on a logarithmic scale.
Python integers and floating point
I used nearly the same code to produce the chart above as I used in its counterpart in the previous post. However, one thing had to change: I couldn’t compute the leading digits of the factorials the same way. Python has extended precision integers, so I can compute 500! factorial without overflowing. Using floating point numbers, I could only go up to 170!. But when I used my previous code to find the leading digit, it first tried to apply log10 to an integer larger than the largest representable floating point number and failed. Converting numbers such as 500! to floating point numbers will overflow. (See Floating point numbers are a leaky abstraction.)
The solution was to find the leading digit using only integer operations.
def leading_digit_int(n):
while n > 9:
n = n/10
return n
This code works fine for numbers like 500! or even larger.
Related: Benford’s law posts grouped by application area