In the introduction to his book Solving Kepler’s Equation Over Three Centuries, Peter Colwell says
In virtually every decade from 1650 to the present there have appeared papers devoted to the Kepler problem and its solution.
This is remarkable because Kepler’s equation isn’t that hard to solve. It cannot be solved in closed form using elementary functions, but it can be solved in many other ways, enough ways for Peter Colwell to write a survey about. One way to find a solution is simply to guess a solution, stick it back in, and iterate. More on that here.
Researchers keep writing about Kepler’s equation, not because it’s hard, but because it’s important. It’s so important that a slightly more efficient solution is significant. Even today with enormous computing resources at our disposal, people are still looking for more efficient solutions. Here’s one that was published last year.
Kepler’s equation
What is Kepler’s equation, and why is it so important?
Kepler’s problem is to solve

for E, given M and e, assuming 0 ≤ M ≤ π and 0 < e < 1.
This equation is important because it essentially tells us how to locate an object in an elliptical orbit. M is mean anomaly, e is eccentricity, and E is eccentric anomaly. Mean anomaly is essentially time. Eccentric anomaly is not exactly the position of the orbiting object, but the position can be easily derived from E. See these notes on mean anomaly and eccentric anomaly. This is because we’re using our increased computing power to track more objects, such as debris in low earth orbit or things that might impact Earth some day.
Newton’s method
A fairly obvious approach to solving Kepler’s equation is to use Newton’s method. I think Newton himself applied his eponymous method to this equation.
Newton’s method is very efficient when it works. As it starts converging, the number of correct decimal places doubles on each iteration. The problem is, however, that it may not converge. When I taught numerical analysis at Vanderbilt, I used a textbook that quoted this nursery rhyme at the beginning of the chapter on Newton’s method.
There was a little girl who had a little curl
Right in the middle of her forehead.
When she was good she was very, very good
But when she was bad she was horrid.
To this day I think of that rhyme every time I use Newton’s method. When Newton’s method is good, it is very, very good, converging quadratically. When it is bad, it can be horrid, pushing you far from the root, and pushing you further away with each iteration. Finding exactly where Newton’s method converges or diverges can be difficult, and the result can be quite complicated. Some fractals are made precisely by separating converging and diverging points.
Newton’s method solves f(x) = 0 by starting with an initial guess x0 an iteratively applies

Notice that
A sufficient condition for Newton’s method to converge is for x0 to belong to a disk around the root where

throughout the disk.
In our case f is the function

where I’ve used x instead of E because Mathematica reserves E for the base of natural logarithms. To see whether the sufficient condition for convergence given above applies, let’s define

Notice that the denominator goes to 0 as e approaches 1, so we should expect difficulty as e increases. That is, we expect Newton’s method might fail for objects in a highly elliptical orbit. However, we are looking at a sufficient condition, not a necessary condition. As I noted here, I used Newton’s method to solve Kepler’s equation for a highly eccentric orbit, hoping for the best, and it worked.
Starting guess
Newton’s method requires a starting guess. Suppose we start by setting E = M. How bad can that guess be? We can find out using Lagrange multipliers. We want to maximize

subject to the constraint that E and E satisfy Kepler’s equation. (We square the difference to get a differentiable objective function to maximize. Minimizing the squared difference minimizes the absolute difference.)
Lagrange’s theorem tells us

and so λ = 2M and

We can conclude that

This says that an initial guess of M is never further than a distance of 1/2 from the solution x, and its even closer when the eccentricity e is small.
If e is less than 0.55 then Newton’s method will converge. We can verify this in Mathematica with
NMaximize[{g[x, e, M], 0 < e < 0.55, 0 <= M <= Pi,
Abs[M - x] < 0.5}, {x, e, M}]
which returns a maximum value of 0.93. The maximum value is an increasing function of the upper bound on e, so converting for e = 0.55 implies converging for e < 0.55. On the other hand, we get a maximum of 1.18 when we let e be as large as 0.60. This doesn’t mean Newton’s method won’t converge, but it means our sufficient condition cannot guarantee that it will converge.
A better starting point
John Machin (1686–1751) came up with a very clever, though mysterious, starting point for solving Kepler’s equation with Newton’s method. Machin didn’t publish his derivation, though later someone was able to reverse engineer how Machin must have been thinking. His starting point is as follows.

This produces an adequate starting point for Newton’s method even for values of e very close to 1.
Notice that you have to solve a cubic equation to find s. That’s messy in general, but it works out cleanly in our case. See the next post for a Python implementation of Newton’s method starting with Machin’s starting point.
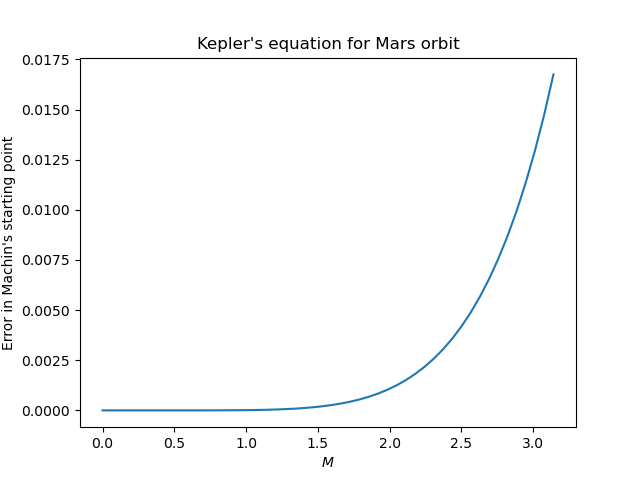
There are simpler starting points that are better than starting with M but not as good as Machin’s method. It may be more efficient to spend less time on the best starting point and more time iterating Newton’s method. On the other hand, if you don’t need much accuracy, and e is not too large, you could use Machin’s starting point as your final value and not use Newton’s method at all. If e < 0.3, as it is for every planet in our solar system, then Machin’s starting point is accurate to 4 decimal places (See Appendix C of Colwell’s book).