The Jacobi elliptic functions sn and cn are analogous to the trigonometric functions sine and cosine. The come up in applications such as nonlinear oscillations and conformal mapping. Unfortunately there are multiple conventions for defining these functions. The purpose of this post is to clear up the confusion around these different conventions.
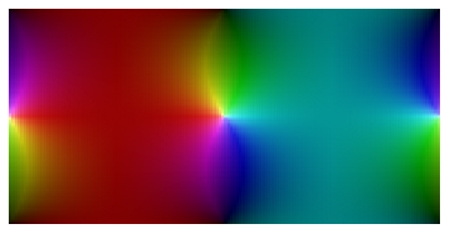
The image above is a plot of the function sn [1].
Modulus, parameter, and modular angle
Jacobi functions take two inputs. We typically think of a Jacobi function as being a function of its first input, the second input being fixed. This second input is a “dial” you can turn that changes their behavior.
There are several ways to specify this dial. I started with the word “dial” rather than “parameter” because in this context parameter takes on a technical meaning, one way of describing the dial. In addition to the “parameter,” you could describe a Jacobi function in terms of its modulus or modular angle. This post will be a Rosetta Stone of sorts, showing how each of these ways of describing a Jacobi elliptic function are related.
The parameter m is a real number in [0, 1]. The complementary parameter is m‘ = 1 − m. Abramowitz and Stegun, for example, write the Jacobi functions sn and cn as sn(u | m) and cn(u | m). They also use m1 = rather than m‘ to denote the complementary parameter.
The modulus k is the square root of m. It would be easier to remember if m stood for modulus, but that’s not conventional. Instead, m is for parameter and k is for modulus. The complementary modulus k‘ is the square root of the complementary parameter.
The modular angle α is defined by m = sin² α.
Note that as the parameter m goes to zero, so does the modulus k and the modular angle α. As any one of these three goes to zero, the Jacobi functions sn and cn converge to their counterparts sine and cosine. So whether your dial is the parameter, modulus, or modular angle, sn converges to sine and cn converges to cosine as you turn the dial toward zero.
As the parameter m goes to 1, so does the modulus k, but the modular angle α goes to π/2. So if your dial is the parameter or the modulus, it goes to 1. But if you think of your dial as modular angle, it goes to π/2. In either case, as you turn the dial to the right as far as it will go, sn converges to hyperbolic secant, and cn converges to the constant function 1.
Quarter periods
In addition to parameter, modulus, and modular angle, you’ll also see Jacobi function described in terms of K and K‘. These are called the quarter periods for good reason. The functions sn and cn have period 4K as you move along the real axis, or move horizontally anywhere in the complex plane. They also have period 4iK‘. That is, the functions repeat when you move a distance 4K‘ vertically [2].
The quarter periods are a function of the modulus. The quarter period K along the real axis is

and the quarter period K‘ along the imaginary axis is given by K‘(m) = K(m‘) = K(1 − m).
The function K(m) is known as “the complete elliptic integral of the first kind.”
Amplitude
So far we’ve focused on the second input to the Jacobi functions, and three conventions for specifying it.
There are two conventions for specifying the first argument, written either as φ or as u. These are related by

The angle φ is called the amplitude. (Yes, it’s an angle, but it’s called an amplitude.)
When we said above that the Jacobi functions had period 4K, this was in terms of the variable u. Note that when φ = π/2, u = K.
Jacobi elliptic functions in Mathematica
Mathematica uses the u convention for the first argument and the parameter convention for the second argument.
The Mathematica function JacobiSN[u, m] computes the function sn with argument u and parameter m. In the notation of A&S, sn(u | m).
Similarly, JacobiCN[u, m] computes the function cn with argument u and parameter m. In the notation of A&S, cn(u | m).
We haven’t talked about the Jacobi function dn up to this point, but it is implemented in Mathematica as JacobiDN[u, m].
The function that solves for the amplitude φ as a function of u is JacobiAmplitude[um m].
The function that computes the quarter period K from the parameter m is EllipticK[m].
Jacobi elliptic functions in Python
The SciPy library has one Python function that computes four mathematical functions at once. The function scipy.special.ellipj takes two arguments, u and m, just like Mathematica, and returns sn(u | m), cn(u | m), dn(u | m), and the amplitude φ(u, m).
The function K(m) is implemented in Python as scipy.special.ellipk.
Related posts
[1] The plot was made using JacobiSN[0.5, z] and the function ComplexPlot described here.
[2] Strictly speaking, 4iK‘ is a period. It’s the smallest vertical period for cn, but 2iK‘ is the smallest vertical period for sn.