Fourier-Bessel series are analogous to Fourier series. And like Fourier series, they converge pointwise near a discontinuity with the same kind of overshoot and undershoot known as the Gibbs phenomenon.
Fourier-Bessel series
Bessel functions come up naturally when working in polar coordinates, just as sines and cosines come up naturally when working in rectangular coordinates. You can think of Bessel functions as a sort of variation on sine waves. Or even more accurately, a variation on sinc functions, where sinc(z) = sin(z)/z. [1]
A Fourier series represents a function as a sum of sines and cosines of different frequencies. To make things a little simpler here, I’ll only consider Fourier sine series so I don’t have to repeatedly say “and cosine.”

A Fourier-Bessel function does something similar. It represents a function as a sum of rescaled versions of a particular Bessel function. We’ll use the Bessel J0 here, but you could pick some other Jν.
Fourier series scale the sine and cosine functions by π times integers, i.e. sin(πz), sin(2πz), sin(3πz), etc. Fourier-Bessel series scale by the zeros of the Bessel function: J0(λ1z), J0(λ2z), J0(λ3z), etc. where λn are the zeros of J0. This is analogous to scaling sin(πz) by its roots: π, 2π, 3π, etc. So a Fourier-Bessel series for a function f looks like

The coefficients cn for Fourier-Bessel series can be computed analogously to Fourier coefficients, but with a couple minor complications. First, the basis functions of a Fourier series are orthogonal over [0, 1] without any explicit weight, i.e. with weight 1. And second, the inner product of a basis function doesn’t depend on the frequency. In detail,

Here δmn equals 1 if m = n and 0 otherwise.
Fourier-Bessel basis functions are orthogonal with a weight z, and the inner product of a basis function with itself depends on the frequency. In detail

So whereas the coefficients for a Fourier sine series are given by

the coefficients for a Fourier-Bessel series are given by

Gibbs phenomenon
Fourier and Fourier-Bessel series are examples of orthogonal series, and so by construction they converge in the norm given by their associated inner product. That means that if SN is the Nth partial sum of a Fourier series

and the analogous statement for a Fourier-Bessel series is

In short, the series converge in a (weighted) L² norm. But how do the series converge pointwise? A lot of harmonic analysis is devoted to answering this question, what conditions on the function f guarantee what kind of behavior of the partial sums of the series expansion.
If we look at the Fourier series for a step function, the partial sums converge pointwise everywhere except at the step discontinuity. But the way they converge is interesting. You get a sort of “bat ear” phenomena where the partial sums overshoot the step function at the discontinuity. This is called the Gibbs phenomenon after Josiah Willard Gibbs who observed the effect in 1899. (Henry Wilbraham observed the same thing earlier, but Gibbs didn’t know that.)
The Gibbs phenomena is well known for Fourier series. It’s not as well known that the same phenomenon occurs for other orthogonal series, such as Fourier-Bessel series. I’ll give an example of Gibbs phenomenon for Fourier-Bessel series taken from [2] and give Python code to visualize it.
We take our function f(z) to be 1 on [0, 1/2] and 0 on (1/2, 1]. It works out that

Python code and plot
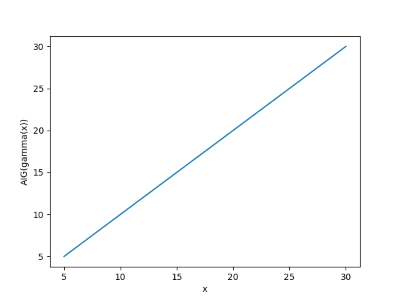
Here’s the plot with 100 terms. Notice how the partial sums overshoot the mark to the left of 1/2 and undershoot to the right of 1/2.

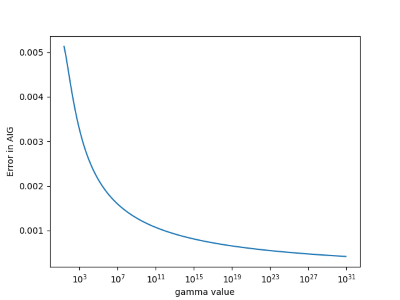
Here’s the same plot with 1,000 terms.

Here’s the Python code that produced the plot.
import matplotlib.pyplot as plt
from scipy.special import j0, j1, jn_zeros
from scipy import linspace
N = 100 # number of terms in series
roots = jn_zeros(0, N)
coeff = [j1(r/2) / (r*j1(r)**2) for r in roots]
z = linspace(0, 1, 200)
def partial_sum(z):
return sum( coeff[i]*j0(roots[i]*z) for i in range(N) )
plt.plot(z, partial_sum(z))
plt.xlabel("z")
plt.ylabel("{}th partial sum".format(N))
plt.show()
Footnotes
[1] To be precise, as z goes to infinity
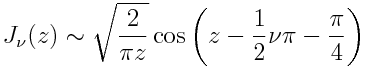
and so the Bessel functions are asymptotically proportional to sin(z – φ)/√z for some phase shift φ.
[2] The Gibbs’ phenomenon for Fourier-Bessel Series. Temple H. Fay and P. Kendrik Kloppers. International Journal of Mathematical Education in Science and Technology. 2003. vol. 323, no. 2, 199-217.